npj Quantum Information ( IF 6.6 ) Pub Date : 2019-10-04 , DOI: 10.1038/s41534-019-0198-z Han Xu , Junning Li , Liqiang Liu , Yu Wang , Haidong Yuan , Xin Wang
|
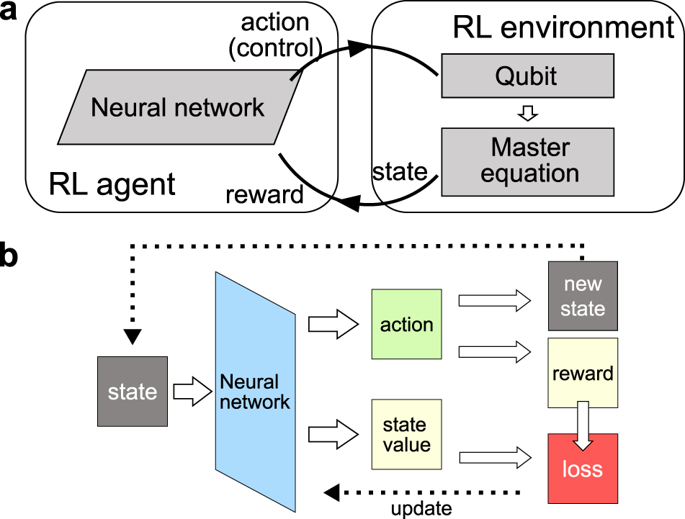
Measurement and estimation of parameters are essential for science and engineering, where one of the main quests is to find systematic schemes that can achieve high precision. While conventional schemes for quantum parameter estimation focus on the optimization of the probe states and measurements, it has been recently realized that control during the evolution can significantly improve the precision. The identification of optimal controls, however, is often computationally demanding, as typically the optimal controls depend on the value of the parameter which then needs to be re-calculated after the update of the estimation in each iteration. Here we show that reinforcement learning provides an efficient way to identify the controls that can be employed to improve the precision. We also demonstrate that reinforcement learning is highly generalizable, namely the neural network trained under one particular value of the parameter can work for different values within a broad range. These desired features make reinforcement learning an efficient alternative to conventional optimal quantum control methods.
中文翻译:
通过强化学习进行量子参数估计的通用控制
参数的测量和估计对于科学和工程至关重要,其中主要的任务之一是寻找可以实现高精度的系统方案。虽然用于量子参数估计的常规方案集中于探针状态和测量的优化,但是最近已经认识到,在演化过程中进行控制可以显着提高精度。然而,最佳控制的识别通常在计算上是需要的,因为最佳控制通常取决于参数的值,然后在每次迭代中更新估计值之后就需要重新计算该参数。在这里,我们显示强化学习提供了一种有效的方法来识别可以用来提高精度的控件。我们还证明了强化学习是高度通用的,即在参数的一个特定值下训练的神经网络可以在很宽的范围内适用于不同的值。这些所需的特征使强化学习成为常规最佳量子控制方法的有效替代方案。










































 京公网安备 11010802027423号
京公网安备 11010802027423号