Neural Processing Letters ( IF 2.6 ) Pub Date : 2022-09-20 , DOI: 10.1007/s11063-022-11031-0 Shuai Zhao , Qing Li , Tengjiao He , Jinming Wen
|
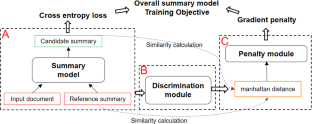
The summary generation model equipped with gradient penalty avoids overfitting and makes the model more stable. However, the traditional gradient penalty faces two issues: (i) calculating the gradient twice increases training time, and (ii) the disturbance factor requires repeated trials to find the best value. To this end, we propose a step-by-step gradient penalty model with similarity calculation (S2SGP). Firstly, the step-by-step gradient penalty is applied to the summary generation model, effectively reducing the training time without sacrificing accuracy. Secondly, the similarity score between reference and candidate summary is calculated as disturbance factor. To show the performance of our proposed solution, we conduct experiments on four summary generation datasets, among which the EDUSum dataset is newly produced by us. Experimental results show that S2SGP effectively reduces training time, and the disturbance factors do not rely on repeated trials. Especially, our model outperforms the baseline by more than 2.4 ROUGE-L points when tested on the CSL dataset.
中文翻译:
用于文本摘要生成的具有相似性计算的逐步梯度惩罚
配备梯度惩罚的摘要生成模型避免了过拟合,使模型更加稳定。然而,传统的梯度惩罚面临两个问题:(i)两次计算梯度会增加训练时间,(ii)干扰因子需要反复试验才能找到最佳值。为此,我们提出了一种具有相似度计算的逐步梯度惩罚模型(S2SGP)。首先,将逐步梯度惩罚应用于摘要生成模型,在不牺牲准确性的情况下有效减少了训练时间。其次,参考和候选摘要之间的相似度得分被计算为干扰因素。为了展示我们提出的解决方案的性能,我们对四个摘要生成数据集进行了实验,其中 EDUSum 数据集是我们新生成的。实验结果表明,S2SGP有效减少了训练时间,干扰因素不依赖于重复试验。特别是,在 CSL 数据集上进行测试时,我们的模型优于基线超过 2.4 ROUGE-L 点。










































 京公网安备 11010802027423号
京公网安备 11010802027423号