
Abstract
The summary generation model equipped with gradient penalty avoids overfitting and makes the model more stable. However, the traditional gradient penalty faces two issues: (i) calculating the gradient twice increases training time, and (ii) the disturbance factor requires repeated trials to find the best value. To this end, we propose a step-by-step gradient penalty model with similarity calculation (S2SGP). Firstly, the step-by-step gradient penalty is applied to the summary generation model, effectively reducing the training time without sacrificing accuracy. Secondly, the similarity score between reference and candidate summary is calculated as disturbance factor. To show the performance of our proposed solution, we conduct experiments on four summary generation datasets, among which the EDUSum dataset is newly produced by us. Experimental results show that S2SGP effectively reduces training time, and the disturbance factors do not rely on repeated trials. Especially, our model outperforms the baseline by more than 2.4 ROUGE-L points when tested on the CSL dataset.


Similar content being viewed by others
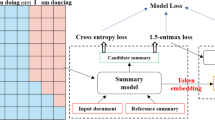

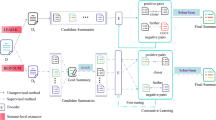
References
Huang D, Cui L, Yang S et al (2020) What have we achieved on text summarization? In: Proceedings of the conference on empirical methods in natural language processing (EMNLP) 2020:446–469
Xu J, Durrett G (2019) Neural extractive text summarization with syntactic compression. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 3292–3303
Zhao Z, Cohen S B, Webber B (2020) Reducing quantity hallucinations in abstractive summarization. Findings of the Association for Computational Linguistics: EMNLP 2020: 2237–2249
Xie Q, Dai Z, Hovy E et al (2020) Unsupervised data augmentation for consistency training. Adv Neural Inf Process Syst 33:6256–6268
Chen T, Kornblith S, Norouzi M et al (2020) A simple framework for contrastive learning of visual representations. In: International conference on machine learning. PMLR, 1597–1607
Edunov S, Ott M, Auli M et al (2018) Understanding back-translation at scale. In: Proceedings of the conference on empirical methods in natural language processing, 2018:489–500
Zhang X, Zhao J, LeCun Y (2015) Character-level convolutional networks for text classification. Adv Neural Inf Process Syst 28:649–657
Goodfellow IJ, Shlens J, Szegedy C (2015) Explaining and harnessing adversarial examples. Stat 1050:20
Madry A, Makelov A, Schmidt L et al (2018) Towards deep learning models resistant to adversarial attacks. In: International conference on learning representations
Jianlin Su (2020) A brief talk on adversarial training: significance, methods and thinking. https://spaces.ac.cn/archives/7234. 01 Mar 2020
Ross A, Doshi-Velez F (2018) Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In: Proceedings of the AAAI conference on artificial intelligence 32(1)
Karras T, Laine S, Aila T (2019) A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4401–4410
Bergstra J, Bengio Y (2012) Random search for hyper-parameter optimization. J Mach Learn Res 13(2):281–305
Snoek J, Larochelle H, Adams RP (2012) Practical Bayesian optimization of machine learning algorithms. Adv Neural Inf Process Syst 25
Xiao D, Zhang H, Li Y, et al (2020) Ernie-gen: an enhanced multi-flow pre-training and fine-tuning framework for natural language generation. arXiv:2001.11314,
Zhao S, He T, Wen J (2022) Sparse summary generation. Appl Intell. https://doi.org/10.1007/s10489-022-03450-2
Edmundson HP (1969) New methods in automatic extracting. J ACM (JACM) 16(2):264–285
Mihalcea R, Tarau P (2004) Textrank: Bringing order into text. In: Proceedings of the 2004 conference on empirical methods in natural language processing, 404–411
Liu Y (2019) Fine-tune BERT for extractive summarization. arXiv:1903.10318
Kenton J D M W C, Toutanova L K (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL-HLT, 4171–4186
Bouscarrat L, Bonnefoy A, Peel T et al (2019) STRASS: a light and effective method for extractive summarization based on sentence embeddings. In: Proceedings of the 57th annual meeting of the association for computational linguistics: student research workshop, 243–252
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. In: Advances in neural information processing systems, 5998–6008
Liu Y, Titov I, Lapata M (2019) Single document summarization as tree induction. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, Vol 1 (Long and Short Papers), 1745–1755
Zhang X, Wei F, Zhou M (2019) HIBERT: document level pre-training of hierarchical bidirectional transformers for document summarization. In: Proceedings of the 57th annual meeting of the association for computational linguistics, 5059–5069
Zhong M, Liu P, Chen Y et al (2020) Extractive summarization as text matching. In: Proceedings of the 58th annual meeting of the association for computational linguistics, 6197–6208
Rush AM, Chopra S, Weston J (2015) A neural attention model for abstractive sentence summarization. In: Proceedings of the conference on empirical methods in natural language processing, 2015:379–389
Gu J, Lu Z, Li H et al (2016) Incorporating copying mechanism in sequence-to-sequence learning. In: Proceedings of the 54th annual meeting of the association for computational linguistics (Vo 1: Long Papers), 1631–1640
See A, Liu PJ, Manning CD (2017) Get to the point: summarization with pointer-generator networks. In: Proceedings of the 55th annual meeting of the association for computational linguistics (Vol 1: Long Papers), 1073–1083
Paulus R, Xiong C, Socher R (2018) A deep reinforced model for abstractive summarization. In: International conference on learning representations
Liu L, Lu Y, Yang M et al (2018) Generative adversarial network for abstractive text summarization. In: Thirty-second AAAI conference on artificial intelligence
Ayd1n S, Güdücü Ç, Kutluk F et al (2019) The impact of musical experience on neural sound encoding performance. Neurosci Lett 694:124-128
Ayd1n S (2011) Computer based synchronization analysis on sleep EEG in insomnia. J Med Syst 35(4):517–520
Liu Y, Lapata M (2019) Text summarization with pretrained encoders. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 3730–3740
Lin C Y (2003) Automatic evaluation of summaries using N-gram cooccurrence statistics. The association for computational linguistics 1
Lewis M, Liu Y, Goyal N et al (2020) BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In: Proceedings of the 58th annual meeting of the association for computational linguistics, 7871–7880
Dong L, Yang N, Wang W et al (2019) Unified language model pre-training for natural language understanding and generation. In: Proceedings of the 33rd international conference on neural information processing systems, 13063–13075
Coulombe C (2018) Text data augmentation made simple by leveraging nlp cloud apis. arXiv:1812.04718
Xie Z, Wang SI, Li J et al (2019) Data noising as smoothing in neural network language models. In: 5th international conference on learning representations, ICLR 2017
Wei J, Zou K (2019) EDA: easy data augmentation techniques for boosting performance on text classification tasks. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 6382–6388
Guo H, Mao Y, Zhang R (2019) Augmenting data with mixup for sentence classification: an empirical study. arXiv:1905.08941
Wu X, Lv S, Zang L, et al (2019) Conditional bert contextual augmentation. In: International conference on computational science. Springer, Cham, 84–95
Qu Y, Shen D, Shen Y et al (2020) CoDA: contrast-enhanced and diversity-promoting data augmentation for natural language understanding. In: International conference on learning representations
Srivastava N, Hinton G, Krizhevsky A et al (2014) Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res 15(1):1929–1958
He K, Zhang X, Ren S et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778
Ma S, Sun X (2017) A semantic relevance based neural network for text summarization and text simplification. Comput Linguist 1(1)
Chang DJ, Desoky AH, Ouyang M et al (2009) Compute pairwise manhattan distance and pearson correlation coefficient of data points with gpu. In: 10th ACIS International Conference on Software Engineering, Artificial Intelligences, Networking and Parallel/Distributed Computing. IEEE, pp 501–506
Hu B, Chen Q, Zhu F (2015) LCSTS: a large scale chinese short text summarization dataset. In: Proceedings of the conference on empirical methods in natural language processing, 2015:1967–1972
Papineni K, Roukos S, Ward T et al (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 311–318
Schütze H, Manning CD, Raghavan P (2008) Introduction to information retrieval. Cambridge University Press, Cambridge
Song K, Tan X, Qin T et al (2019) MASS: masked sequence to sequence pre-training for language generation. In: International conference on machine learning. PMLR, 5926–5936
Yadav AK, Singh A, Dhiman M et al (2022) Extractive text summarization using deep learning approach. Int J Inf Technol 1-9
Clarke J, Lapata M (2008) Global inference for sentence compression: an integer linear programming approach. J Artif Intell Res 31:399–429
Ott M, Edunov S, Baevski A et al (2019) fairseq: a fast, extensible toolkit for sequence modeling. In: Proceedings of the conference of the North American chapter of the association for computational linguistics (Demonstrations), 2019:48–53
Lan Z, Chen M, Goodman S et al (2019) ALBERT: a lite BERT for self-supervised learning of language representations. In: International conference on learning representations
Wei J, Ren X, Li X et al (2019) Nezha: neural contextualized representation for Chinese language understanding. arXiv:1909.00204
Cui Y, Che W, Liu T et al (2021) Pre-training with whole word masking for Chinese bert. IEEE/ACM Trans Audio Speech Lang Process 29:3504–3514
Acknowledgements
This work was partially supported by National Natural Science Foundation of China (Nos.11871248, 12271215), Natural Science Foundation of Guangdong Province of China (2021A515010857, 2022A1515010029), the China Scholarship Council (CSC) (Grant No. 202206780011).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhao, S., Li, Q., He, T. et al. A Step-by-Step Gradient Penalty with Similarity Calculation for Text Summary Generation. Neural Process Lett 55, 4111–4126 (2023). https://doi.org/10.1007/s11063-022-11031-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-022-11031-0