Journal of Iron and Steel Research International ( IF 3.1 ) Pub Date : 2022-04-13 , DOI: 10.1007/s42243-022-00773-9 Zheng Wang 1 , Hai-wen Luo 1 , Yue-hui Guan 2
|
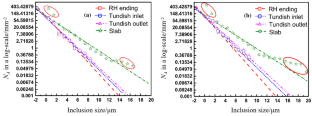
Non-metallic inclusions are critical for the fatigue failure of clean steels in service; especially, the large and hard inclusions are detrimental. Since it is not possible to measure all the inclusions in the large-volume clean steels, statistical models have been developed to evaluate inclusions, aiming at predicting the maximum inclusion size in the large volume from the data of inclusions, which are derived from the limited observations on small-volume specimens. Different statistical models were reviewed together with their supporting theories. In particular, the block maxima and the threshold types of models were discussed through a thorough comparison as they are both widely used and based on the extreme value theory. The predicted results not only are used to distinguish the different cleanliness levels of steels, but also help to estimate fatigue strength. Finally, future research is proposed to focus on tackling the present difficulties encountered by statistical models, including the sufficient credibility of obtained results and the robustness of models for applications.
中文翻译:
洁净钢中夹杂物评价统计模型的研究进展
非金属夹杂物对使用中的清洁钢的疲劳失效至关重要;特别是大而硬的夹杂物是有害的。由于不可能测量大体积洁净钢中的所有夹杂物,因此开发了统计模型来评估夹杂物,旨在根据夹杂物数据预测大体积夹杂物的最大尺寸,这些数据来源于有限的夹杂物。对小体积标本的观察。对不同的统计模型及其支持理论进行了回顾。特别是,通过彻底比较讨论了块最大值和阈值类型的模型,因为它们都被广泛使用并基于极值理论。预测结果不仅用于区分不同清洁度等级的钢材,还有助于估算疲劳强度。最后,提出未来的研究重点是解决统计模型目前遇到的困难,包括所得结果的足够可信度和应用模型的稳健性。








































 京公网安备 11010802027423号
京公网安备 11010802027423号