Interdisciplinary Sciences: Computational Life Sciences ( IF 3.9 ) Pub Date : 2021-06-18 , DOI: 10.1007/s12539-021-00448-1 Qizhi Zhu 1, 2 , Lihua Wang 1, 2 , Ruyu Dai 2 , Wei Zhang 2 , Wending Tang 2 , Yannan Bin 2 , Zeliang Wang 1 , Junfeng Xia 2
|
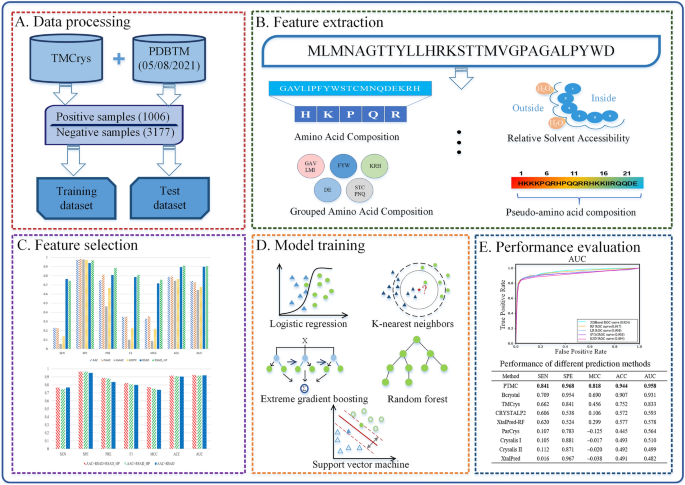
Transmembrane proteins play a vital role in cell life activities. There are several techniques to determine transmembrane protein structures and X-ray crystallography is the primary methodology. However, due to the special properties of transmembrane proteins, it is still hard to determine their structures by X-ray crystallography technique. To reduce experimental consumption and improve experimental efficiency, it is of great significance to develop computational methods for predicting the crystallization propensity of transmembrane proteins. In this work, we proposed a sequence-based machine learning method, namely Prediction of TransMembrane protein Crystallization propensity (PTMC), to predict the propensity of transmembrane protein crystallization. First, we obtained several general sequence features and the specific encoded features of relative solvent accessibility and hydrophobicity. Second, feature selection was employed to filter out redundant and irrelevant features, and the optimal feature subset is composed of hydrophobicity, amino acid composition and relative solvent accessibility. Finally, we chose extreme gradient boosting by comparing with other several machine learning methods. Comparative results on the independent test set indicate that PTMC outperforms state-of-the-art sequence-based methods in terms of sensitivity, specificity, accuracy, Matthew's Correlation Coefficient (MCC) and Area Under the receiver operating characteristic Curve (AUC). In comparison with two competitors, Bcrystal and TMCrys, PTMC achieves an improvement by 0.132 and 0.179 for sensitivity, 0.014 and 0.127 for specificity, 0.037 and 0.192 for accuracy, 0.128 and 0.362 for MCC, and 0.027 and 0.125 for AUC, respectively.
Graphic abstract
中文翻译:
基于序列的跨膜蛋白结晶倾向预测
跨膜蛋白在细胞生命活动中起着至关重要的作用。有多种技术可以确定跨膜蛋白结构,而 X 射线晶体学是主要方法。然而,由于跨膜蛋白的特殊性质,X射线晶体学技术仍难以确定其结构。为了减少实验消耗和提高实验效率,开发预测跨膜蛋白结晶倾向的计算方法具有重要意义。在这项工作中,我们提出了一种基于序列的机器学习方法,即跨膜蛋白结晶倾向预测(PTMC),来预测跨膜蛋白结晶的倾向。第一的,我们获得了几个一般序列特征和相对溶剂可及性和疏水性的特定编码特征。其次,采用特征选择过滤掉多余和不相关的特征,最优特征子集由疏水性、氨基酸组成和相对溶剂可及性组成。最后,通过与其他几种机器学习方法进行比较,我们选择了极端梯度提升。独立测试集上的比较结果表明,PTMC 在灵敏度、特异性、准确性、马修相关系数 (MCC) 和接受者操作特征曲线下面积 (AUC) 方面优于最先进的基于序列的方法。与两个竞争对手 Bcrystal 和 TMCrys 相比,PTMC 的灵敏度分别提高了 0.132 和 0.179,分别为 0.014 和 0。










































 京公网安备 11010802027423号
京公网安备 11010802027423号