当前位置:
X-MOL 学术
›
WIREs Comput. Mol. Sci.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Formatting biological big data for modern machine learning in drug discovery
Wiley Interdisciplinary Reviews: Computational Molecular Science ( IF 16.8 ) Pub Date : 2018-12-27 , DOI: 10.1002/wcms.1408 Miquel Duran‐Frigola 1 , Adrià Fernández‐Torras 1 , Martino Bertoni 1 , Patrick Aloy 1, 2
Wiley Interdisciplinary Reviews: Computational Molecular Science ( IF 16.8 ) Pub Date : 2018-12-27 , DOI: 10.1002/wcms.1408 Miquel Duran‐Frigola 1 , Adrià Fernández‐Torras 1 , Martino Bertoni 1 , Patrick Aloy 1, 2
Affiliation
|
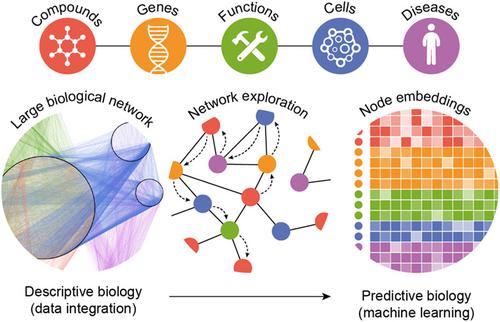
Biological data is accumulating at an unprecedented rate, escalating the role of data‐driven methods in computational drug discovery. This scenario is favored by recent advances in machine learning algorithms, which are optimized for huge datasets and consistently beat the predictive performance of previous art, rapidly approaching human expert reasoning. The urge to couple biological data to cutting‐edge machine learning has spurred developments in data integration and knowledge representation, especially in the form of heterogeneous, multiplex and semantically‐rich biological networks. Today, thanks to the propitious rise in knowledge embedding techniques, these large and complex biological networks can be converted to a vector format that suits the majority of machine learning implementations. Here, we explain why this can be particularly transformative for drug discovery where, for decades, customary chemoinformatics methods have employed vector descriptors of compound structures as the standard input of their prediction tasks. A common vector format to represent biology and chemistry may push biological information into most of the existing steps of the drug discovery pipeline, boosting the accuracy of predictions and uncovering connections between small molecules and other biological entities such as targets or diseases.
中文翻译:

格式化生物大数据以用于药物发现中的现代机器学习
生物数据正以前所未有的速度积累,从而逐步提升了数据驱动方法在药物研发中的作用。机器学习算法的最新进展为这种情况提供了支持,该算法已针对庞大的数据集进行了优化,并且始终优于现有技术的预测性能,从而迅速接近了人类专家的推理。将生物数据耦合到最先进的机器学习的冲动刺激了数据集成和知识表示的发展,特别是以异构,多重和语义丰富的生物网络的形式。如今,由于知识嵌入技术的兴起,这些庞大而复杂的生物网络可以转换为适合大多数机器学习实现的矢量格式。这里,我们解释了为什么这对于药物发现可能具有特别的变革意义,因为数十年来,常规化学信息学方法一直采用化合物结构的矢量描述符作为其预测任务的标准输入。代表生物学和化学的通用载体格式可能会将生物学信息推入药物发现流程的大多数现有步骤中,从而提高了预测的准确性,并揭示了小分子与其他生物实体(例如靶标或疾病)之间的联系。
更新日期:2019-05-16
中文翻译:
格式化生物大数据以用于药物发现中的现代机器学习
生物数据正以前所未有的速度积累,从而逐步提升了数据驱动方法在药物研发中的作用。机器学习算法的最新进展为这种情况提供了支持,该算法已针对庞大的数据集进行了优化,并且始终优于现有技术的预测性能,从而迅速接近了人类专家的推理。将生物数据耦合到最先进的机器学习的冲动刺激了数据集成和知识表示的发展,特别是以异构,多重和语义丰富的生物网络的形式。如今,由于知识嵌入技术的兴起,这些庞大而复杂的生物网络可以转换为适合大多数机器学习实现的矢量格式。这里,我们解释了为什么这对于药物发现可能具有特别的变革意义,因为数十年来,常规化学信息学方法一直采用化合物结构的矢量描述符作为其预测任务的标准输入。代表生物学和化学的通用载体格式可能会将生物学信息推入药物发现流程的大多数现有步骤中,从而提高了预测的准确性,并揭示了小分子与其他生物实体(例如靶标或疾病)之间的联系。










































 京公网安备 11010802027423号
京公网安备 11010802027423号