当前位置:
X-MOL 学术
›
Anal. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Detection of Outliers in Projection-Based Modeling.
Analytical Chemistry ( IF 6.7 ) Pub Date : 2020-01-13 , DOI: 10.1021/acs.analchem.9b04611 Oxana Ye Rodionova 1 , Alexey L Pomerantsev 1
Analytical Chemistry ( IF 6.7 ) Pub Date : 2020-01-13 , DOI: 10.1021/acs.analchem.9b04611 Oxana Ye Rodionova 1 , Alexey L Pomerantsev 1
Affiliation
|
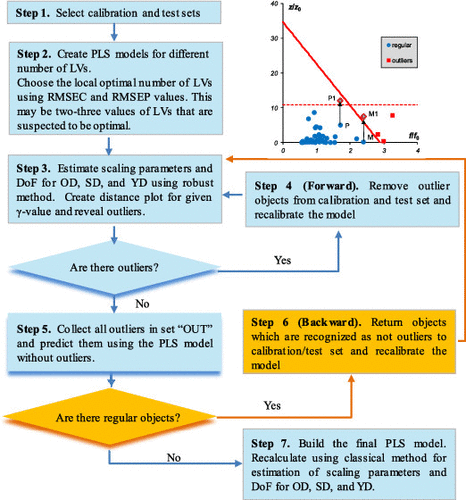
Previously, we have introduced an approach for calculation of the full object distance in the frame of Principal Component Analysis that can be applied to data exploration and classification. Now, a similar approach has been developed for regression problems in which a total distance can be calculated for every sample in projection modeling. Based on the total distance, a threshold for outlier detection has been developed by means of a data-driven estimation of the degrees of freedom and scaling parameters for the partial distances in the projection models. A joint threshold is used as a basis for a sequential outlier detection procedure. The iterative nature of the procedure helps to overcome masking effect in outliers, and a backward step eliminates swamping effects. Two real examples are used for illustration. The first dataset represents capsules filled with specially prepared mixtures of an active pharmaceutical ingredient and a number of excipients. This dataset is used to illustrate the behavior of possible outliers in the regression model and their corresponding locations in the X- and XY-distance plots. The second dataset consists of spectra of 135 whole wheat samples used for the prediction of protein, gluten, and moisture content. This dataset is used for a demonstration of the step-by-step application of the sequential procedure for outlier detection.
中文翻译:

基于投影的建模中离群值的检测。
以前,我们介绍了一种在主成分分析框架内计算整个物体距离的方法,该方法可用于数据探索和分类。现在,已经针对回归问题开发了一种类似的方法,其中可以在投影建模中为每个样本计算总距离。基于总距离,已通过数据驱动的投影模型中部分距离的自由度和缩放参数的数据驱动估计,开发了用于离群值检测的阈值。联合阈值用作顺序异常值检测过程的基础。该过程的迭代性质有助于克服异常值中的掩盖效应,而后退步骤则可以消除沼泽效应。两个真实的例子用于说明。第一个数据集代表装有特别制备的活性药物成分和多种赋形剂混合物的胶囊。该数据集用于说明回归模型中可能的异常值的行为及其在X和XY距离图中的对应位置。第二个数据集由135个全麦样品的光谱组成,用于预测蛋白质,面筋和水分含量。此数据集用于演示离群值检测的顺序过程的逐步应用。第二个数据集由135个全麦样品的光谱组成,这些光谱用于预测蛋白质,面筋和水分含量。此数据集用于演示离群值检测的顺序过程的逐步应用。第二个数据集由135个全麦样品的光谱组成,这些光谱用于预测蛋白质,面筋和水分含量。此数据集用于演示离群值检测的顺序过程的逐步应用。
更新日期:2020-01-14
中文翻译:
基于投影的建模中离群值的检测。
以前,我们介绍了一种在主成分分析框架内计算整个物体距离的方法,该方法可用于数据探索和分类。现在,已经针对回归问题开发了一种类似的方法,其中可以在投影建模中为每个样本计算总距离。基于总距离,已通过数据驱动的投影模型中部分距离的自由度和缩放参数的数据驱动估计,开发了用于离群值检测的阈值。联合阈值用作顺序异常值检测过程的基础。该过程的迭代性质有助于克服异常值中的掩盖效应,而后退步骤则可以消除沼泽效应。两个真实的例子用于说明。第一个数据集代表装有特别制备的活性药物成分和多种赋形剂混合物的胶囊。该数据集用于说明回归模型中可能的异常值的行为及其在X和XY距离图中的对应位置。第二个数据集由135个全麦样品的光谱组成,用于预测蛋白质,面筋和水分含量。此数据集用于演示离群值检测的顺序过程的逐步应用。第二个数据集由135个全麦样品的光谱组成,这些光谱用于预测蛋白质,面筋和水分含量。此数据集用于演示离群值检测的顺序过程的逐步应用。第二个数据集由135个全麦样品的光谱组成,这些光谱用于预测蛋白质,面筋和水分含量。此数据集用于演示离群值检测的顺序过程的逐步应用。










































 京公网安备 11010802027423号
京公网安备 11010802027423号