当前位置:
X-MOL 学术
›
J. Biomed. Inform.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Task definition, annotated dataset, and supervised natural language processing models for symptom extraction from unstructured clinical notes.
Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2019-12-12 , DOI: 10.1016/j.jbi.2019.103354 Jackson M Steinkamp 1 , Wasif Bala 1 , Abhinav Sharma 2 , Jacob J Kantrowitz 3
Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2019-12-12 , DOI: 10.1016/j.jbi.2019.103354 Jackson M Steinkamp 1 , Wasif Bala 1 , Abhinav Sharma 2 , Jacob J Kantrowitz 3
Affiliation
|
INTRODUCTION
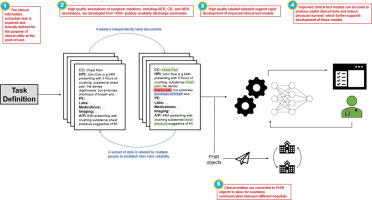
Machine learning (ML) and natural language processing have great potential to improve information extraction (IE) within electronic medical records (EMRs) for a wide variety of clinical search and summarization tools. Despite ML advancements, clinical adoption of real time IE tools for patient care remains low. Clinically motivated IE task definitions, publicly available annotated clinical datasets, and inclusion of subtasks such as coreference resolution and named entity normalization are critical for the development of useful clinical tools.
MATERIALS AND METHODS
We provide a task definition and comprehensive annotation requirements for a clinically motivated symptom extraction task. Four annotators labeled symptom mentions within 1108 discharge summaries from two public clinical note datasets for the tasks of named entity recognition, coreference resolution, and named entity normalization; these annotations will be released to the public. Baseline human performance was assessed and two ML models were evaluated on the symptom extraction task.
RESULTS
16,922 symptom mentions were identified within the discharge summaries, with 11,944 symptom instances after coreference resolution and 1255 unique normalized answer forms. Human annotator performance averaged 92.2% F1. Recurrent network model performance was 85.6% F1 (recall 85.8%, precision 85.4%), and Transformer-based model performance was 86.3% F1 (recall 86.6%, precision 86.1%). Our models extracted vague symptoms, acronyms, typographical errors, and grouping statements. The models generalized effectively to a separate clinical note corpus and can run in real time.
CONCLUSION
To our knowledge, this dataset will be the largest and most comprehensive publicly released, annotated dataset for clinically motivated symptom extraction, as it includes annotations for named entity recognition, coreference, and normalization for more than 1000 clinical documents. Our neural network models extracted symptoms from unstructured clinical free text at near human performance in real time. In this paper, we present a clinically motivated task definition, dataset, and simple supervised natural language processing models to demonstrate the feasibility of building clinically applicable information extraction tools.
中文翻译:

从非结构化临床笔记中提取症状的任务定义,带注释的数据集和受监督的自然语言处理模型。
简介机器学习(ML)和自然语言处理具有巨大的潜力,可以改善用于各种临床搜索和摘要工具的电子病历(EMR)中的信息提取(IE)。尽管ML取得了进步,但用于患者护理的实时IE工具在临床上的采用率仍然很低。具有临床动机的IE任务定义,可公开获得注释的临床数据集以及包括子任务(例如,共同参照解析和命名实体规范化)对于开发有用的临床工具至关重要。材料和方法我们为临床动机的症状提取任务提供任务定义和全面的注释要求。来自两个公共临床笔记数据集的1108个放电摘要中有四个带注释的症状注释者,用于命名实体识别,共指解析和命名实体归一化;这些注释将公开发布。评估了基线的人类表现,并评估了症状提取任务中的两个ML模型。结果在出院总结中确定了16,922个症状提及,共参考解决后有11,944个症状实例和1255个唯一的标准化答案形式。人类注释者的平均表现为F1 92.2%。循环网络模型的性能为F1的85.6%(召回率为85.8%,精度为85.4%),基于变压器的模型性能为F1的86.3%(召回率为86.6%,精度为86.1%)。我们的模型提取了模糊的症状,首字母缩写词,印刷错误和分组说明。这些模型可以有效地推广到单独的临床笔记语料库,并且可以实时运行。结论据我们所知,该数据集将是针对临床动机症状提取的最大,最全面的公开注释数据集,因为它包含了针对1000多个临床文档的命名实体识别,共同引用和规范化的注释。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。结论据我们所知,该数据集将是用于临床症状提取的最大,最全面的公开注释的数据集,因为它包含了针对1000多个临床文档的命名实体识别,共同引用和规范化的注释。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。结论据我们所知,该数据集将是用于临床症状提取的最大,最全面的公开注释的数据集,因为它包含了针对1000多个临床文档的命名实体识别,共同引用和规范化的注释。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。并标准化了1000多个临床文件。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。并标准化了1000多个临床文件。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。
更新日期:2019-12-13
中文翻译:
从非结构化临床笔记中提取症状的任务定义,带注释的数据集和受监督的自然语言处理模型。
简介机器学习(ML)和自然语言处理具有巨大的潜力,可以改善用于各种临床搜索和摘要工具的电子病历(EMR)中的信息提取(IE)。尽管ML取得了进步,但用于患者护理的实时IE工具在临床上的采用率仍然很低。具有临床动机的IE任务定义,可公开获得注释的临床数据集以及包括子任务(例如,共同参照解析和命名实体规范化)对于开发有用的临床工具至关重要。材料和方法我们为临床动机的症状提取任务提供任务定义和全面的注释要求。来自两个公共临床笔记数据集的1108个放电摘要中有四个带注释的症状注释者,用于命名实体识别,共指解析和命名实体归一化;这些注释将公开发布。评估了基线的人类表现,并评估了症状提取任务中的两个ML模型。结果在出院总结中确定了16,922个症状提及,共参考解决后有11,944个症状实例和1255个唯一的标准化答案形式。人类注释者的平均表现为F1 92.2%。循环网络模型的性能为F1的85.6%(召回率为85.8%,精度为85.4%),基于变压器的模型性能为F1的86.3%(召回率为86.6%,精度为86.1%)。我们的模型提取了模糊的症状,首字母缩写词,印刷错误和分组说明。这些模型可以有效地推广到单独的临床笔记语料库,并且可以实时运行。结论据我们所知,该数据集将是针对临床动机症状提取的最大,最全面的公开注释数据集,因为它包含了针对1000多个临床文档的命名实体识别,共同引用和规范化的注释。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。结论据我们所知,该数据集将是用于临床症状提取的最大,最全面的公开注释的数据集,因为它包含了针对1000多个临床文档的命名实体识别,共同引用和规范化的注释。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。结论据我们所知,该数据集将是用于临床症状提取的最大,最全面的公开注释的数据集,因为它包含了针对1000多个临床文档的命名实体识别,共同引用和规范化的注释。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。并标准化了1000多个临床文件。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。并标准化了1000多个临床文件。我们的神经网络模型可实时以接近人类的表现从非结构化的临床免费文本中提取症状。在本文中,我们提出了一种具有临床动机的任务定义,数据集和简单的受监督的自然语言处理模型,以证明构建具有临床适用性的信息提取工具的可行性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号