当前位置:
X-MOL 学术
›
Kidney Int.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Natural language processing of electronic health records is superior to billing codes to identify symptom burden in hemodialysis patients.
Kidney International ( IF 14.8 ) Pub Date : 2019-11-09 , DOI: 10.1016/j.kint.2019.10.023 Lili Chan 1 , Kelly Beers 2 , Amy A Yau 2 , Kinsuk Chauhan 2 , Áine Duffy 3 , Kumardeep Chaudhary 3 , Neha Debnath 2 , Aparna Saha 3 , Pattharawin Pattharanitima 2 , Judy Cho 3 , Peter Kotanko 4 , Alex Federman 5 , Steven G Coca 2 , Tielman Van Vleck 3 , Girish N Nadkarni 1
Kidney International ( IF 14.8 ) Pub Date : 2019-11-09 , DOI: 10.1016/j.kint.2019.10.023 Lili Chan 1 , Kelly Beers 2 , Amy A Yau 2 , Kinsuk Chauhan 2 , Áine Duffy 3 , Kumardeep Chaudhary 3 , Neha Debnath 2 , Aparna Saha 3 , Pattharawin Pattharanitima 2 , Judy Cho 3 , Peter Kotanko 4 , Alex Federman 5 , Steven G Coca 2 , Tielman Van Vleck 3 , Girish N Nadkarni 1
Affiliation
|
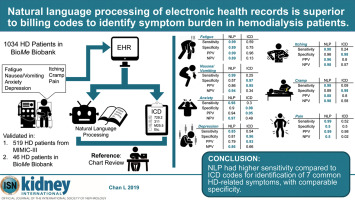
Symptoms are common in patients on maintenance hemodialysis but identification is challenging. New informatics approaches including natural language processing (NLP) can be utilized to identify symptoms from narrative clinical documentation. Here we utilized NLP to identify seven patient symptoms from notes of maintenance hemodialysis patients of the BioMe Biobank and validated our findings using a separate cohort and the MIMIC-III database. NLP performance was compared for symptom detection with International Classification of Diseases (ICD)-9/10 codes and the performance of both methods were validated against manual chart review. From 1034 and 519 hemodialysis patients within BioMe and MIMIC-III databases, respectively, the most frequently identified symptoms by NLP were fatigue, pain, and nausea/vomiting. In BioMe, sensitivity for NLP (0.85 - 0.99) was higher than for ICD codes (0.09 - 0.59) for all symptoms with similar results in the BioMe validation cohort and MIMIC-III. ICD codes were significantly more specific for nausea/vomiting in BioMe and more specific for fatigue, depression, and pain in the MIMIC-III database. A majority of patients in both cohorts had four or more symptoms. Patients with more symptoms identified by NLP, ICD, and chart review had more clinical encounters. NLP had higher specificity in inpatient notes but higher sensitivity in outpatient notes and performed similarly across pain severity subgroups. Thus, NLP had higher sensitivity compared to ICD codes for identification of seven common hemodialysis-related symptoms, with comparable specificity between the two methods. Hence, NLP may be useful for the high-throughput identification of patient-centered outcomes when using electronic health records.
中文翻译:

电子健康记录的自然语言处理优于识别血液透析患者症状负担的计费代码。
维持性血液透析患者的症状很普遍,但鉴定具有挑战性。包括自然语言处理(NLP)在内的新信息学方法可用于从叙述性临床文档中识别症状。在这里,我们利用NLP从BioMe Biobank维持性血液透析患者的笔记中识别出七个患者症状,并使用单独的队列和MIMIC-III数据库验证了我们的发现。将NLP性能与国际疾病分类(ICD)-9/10代码进行症状检测进行了比较,并且两种方法的性能均通过手动图表审查进行了验证。分别从BioMe和MIMIC-III数据库中的1034和519血液透析患者中,通过NLP识别出的最常见症状是疲劳,疼痛和恶心/呕吐。在BioMe中,对NLP的敏感度(0.85-0。99)高于所有症状的ICD代码(0.09-0.59),在BioMe验证队列和MIMIC-III中的结果相似。ICD代码在BioMe中对恶心/呕吐的特异性更强,而在MIMIC-III数据库中对疲劳,抑郁和疼痛的特异性更强。两个队列中的大多数患者都有四个或更多症状。通过NLP,ICD和图表检查确定的症状更多的患者有更多的临床遭遇。NLP在住院记录中具有更高的特异性,但在门诊记录中具有更高的敏感性,并且在疼痛严重程度亚组中的表现相似。因此,与ICD代码相比,NLP具有更高的灵敏度,可识别7种常见的血液透析相关症状,并且两种方法的特异性相当。因此,
更新日期:2019-11-11
中文翻译:
电子健康记录的自然语言处理优于识别血液透析患者症状负担的计费代码。
维持性血液透析患者的症状很普遍,但鉴定具有挑战性。包括自然语言处理(NLP)在内的新信息学方法可用于从叙述性临床文档中识别症状。在这里,我们利用NLP从BioMe Biobank维持性血液透析患者的笔记中识别出七个患者症状,并使用单独的队列和MIMIC-III数据库验证了我们的发现。将NLP性能与国际疾病分类(ICD)-9/10代码进行症状检测进行了比较,并且两种方法的性能均通过手动图表审查进行了验证。分别从BioMe和MIMIC-III数据库中的1034和519血液透析患者中,通过NLP识别出的最常见症状是疲劳,疼痛和恶心/呕吐。在BioMe中,对NLP的敏感度(0.85-0。99)高于所有症状的ICD代码(0.09-0.59),在BioMe验证队列和MIMIC-III中的结果相似。ICD代码在BioMe中对恶心/呕吐的特异性更强,而在MIMIC-III数据库中对疲劳,抑郁和疼痛的特异性更强。两个队列中的大多数患者都有四个或更多症状。通过NLP,ICD和图表检查确定的症状更多的患者有更多的临床遭遇。NLP在住院记录中具有更高的特异性,但在门诊记录中具有更高的敏感性,并且在疼痛严重程度亚组中的表现相似。因此,与ICD代码相比,NLP具有更高的灵敏度,可识别7种常见的血液透析相关症状,并且两种方法的特异性相当。因此,










































 京公网安备 11010802027423号
京公网安备 11010802027423号