Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2019-10-31 , DOI: 10.1016/j.jbi.2019.103324 Muhammad Abulaish 1 , Md Aslam Parwez 2 , Jahiruddin 2
|
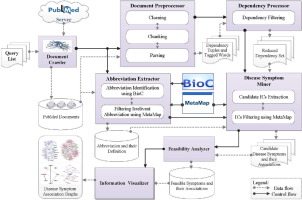
Due to increasing volume and unstructured nature of the scientific literatures in biomedical domain, most of the information embedded within them remain untapped. This paper presents a biomedical text analytics system, DiseaSE (Disease Symptom Extraction), to identify and extract disease symptoms and their associations from biomedical text documents retrieved from the PubMed database. It implements various NLP and information extraction techniques to convert text documents into record-size information components that are represented as semantic triples and processed using TextRank and other ranking techniques to identify feasible disease symptoms. Eight different diseases, including dengue, malaria, cholera, diarrhoea, influenza, meningitis, leishmaniasis, and kala-azar are considered for experimental evaluation of the proposed DiseaSE system. On analysis, we found that the DiseaSE system is able to identify new symptoms that are even not catalogued on standard websites such as Center for Disease Control (CDC), World Health Organization (WHO), and National Health Survey (NHS). The proposed DiseaSE system also aims to compile generic associations between a disease and its symptoms, and presents a graph-theoretic analysis and visualization scheme to characterize disease at different levels of granularity. The identified disease symptoms and their associations could be useful to generate a biomedical knowledgebase (e.g., a disease ontology) for the development of e-health and disease surveillance systems.
中文翻译:
DiseaSE:一种生物医学文本分析系统,用于疾病症状的提取和表征。
由于生物医学领域科学文献的数量不断增加且结构无序,因此其中嵌入的大多数信息仍未得到开发。本文提出了一种生物医学文本分析系统,疾病(Disea SE小号ymptom ē xtraction),识别并提取疾病症状,从检索到的生物医学文本文档及其关联考研数据库。它实现了各种NLP和信息提取技术,可将文本文档转换为记录大小的信息组件,这些信息组件表示为语义三元组并使用TextRank处理和其他分级技术来确定可行的疾病症状。拟议的DiseaSE系统的实验评估考虑了八种不同的疾病,包括登革热,疟疾,霍乱,腹泻,流感,脑膜炎,利什曼病和黑热病。经过分析,我们发现DiseaSE系统能够识别甚至在标准网站(如疾病控制中心(CDC),世界卫生组织(WHO)和国家健康调查(NHS))上未分类的新症状。拟议中的DiseaSE该系统还旨在汇编疾病及其症状之间的通用关联,并提出一种图形理论分析和可视化方案来表征不同粒度级别的疾病。所确定的疾病症状及其关联可能有助于生成生物医学知识库(例如,疾病本体),以开发电子医疗和疾病监测系统。










































 京公网安备 11010802027423号
京公网安备 11010802027423号