当前位置:
X-MOL 学术
›
ACS Comb. Sci.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Metric Learning for High-Throughput Combinatorial Data Sets.
ACS Combinatorial Science Pub Date : 2019-10-31 , DOI: 10.1021/acscombsci.9b00086 Kiran Vaddi 1 , Olga Wodo 1
ACS Combinatorial Science Pub Date : 2019-10-31 , DOI: 10.1021/acscombsci.9b00086 Kiran Vaddi 1 , Olga Wodo 1
Affiliation
|
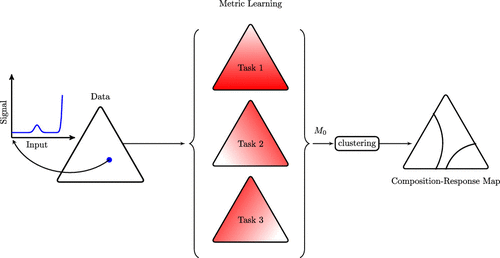
Materials design and discovery through the high-throughput exploration of materials space has been recognized as a new paradigm in materials science. However, typical high-throughput exploration methods deliver high-dimensional and very diverse data sets that pose the challenge of extracting the key features and patterns that could guide the discovery process. Unraveling patterns is a nontrivial task as quite often the underlying physical phenomena are uncertain and latent variables governing the performance are mainly unknown. In this paper, we discuss challenges related to designing a data analytics tool for clustering high-throughput measurements performed on the compositional library of materials. The critical aspects of our methodology are (i) learning the similarity measures, as opposed to using fixed similarity measures (e.g., Euclidean distance, dynamic time warping), while (ii) imposing the similarity in the composition space. Our methodology is based on the multitask learning approach that is formulated to account for the composition neighborhoods that are specific to the compositional libraries. We demonstrate the advantages of our methodology for the library of cyclic voltammetry curves generated for model multimetal catalysts, as well as X-ray diffraction patterns from experimental studies. We also compare our approach with the current state-of-the-art methods used in similar problems. This work has important implications for designing high-throughput exploration including catalysts for electrochemical systems, such as fuel cells and metal-air batteries.
中文翻译:

高通量组合数据集的度量学习。
通过对材料空间的高通量探索来进行材料设计和发现已被认为是材料科学的新范式。但是,典型的高通量探索方法会提供高维且非常多样化的数据集,这给提取可指导发现过程的关键特征和模式带来了挑战。展开模式是一项艰巨的任务,因为通常潜在的物理现象是不确定的,而控制性能的潜变量主要是未知的。在本文中,我们讨论了与设计数据分析工具有关的挑战,该工具用于对在材料成分库中执行的高通量测量进行聚类。我们方法论的关键方面是(i)学习相似性度量,而不是使用固定的相似性度量(例如,欧氏距离,动态时间扭曲),而(ii)在构图空间中施加相似性。我们的方法基于多任务学习方法,该方法旨在解决成分库特定的成分邻域问题。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们的方法基于多任务学习方法,该方法旨在解决成分库特定的成分邻域问题。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们的方法基于多任务学习方法,该方法旨在解决成分库特定的成分邻域问题。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。
更新日期:2019-11-01
中文翻译:
高通量组合数据集的度量学习。
通过对材料空间的高通量探索来进行材料设计和发现已被认为是材料科学的新范式。但是,典型的高通量探索方法会提供高维且非常多样化的数据集,这给提取可指导发现过程的关键特征和模式带来了挑战。展开模式是一项艰巨的任务,因为通常潜在的物理现象是不确定的,而控制性能的潜变量主要是未知的。在本文中,我们讨论了与设计数据分析工具有关的挑战,该工具用于对在材料成分库中执行的高通量测量进行聚类。我们方法论的关键方面是(i)学习相似性度量,而不是使用固定的相似性度量(例如,欧氏距离,动态时间扭曲),而(ii)在构图空间中施加相似性。我们的方法基于多任务学习方法,该方法旨在解决成分库特定的成分邻域问题。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们的方法基于多任务学习方法,该方法旨在解决成分库特定的成分邻域问题。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们的方法基于多任务学习方法,该方法旨在解决成分库特定的成分邻域问题。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。我们展示了我们的方法的优势,该方法可用于为模型多金属催化剂生成的循环伏安曲线库,以及来自实验研究的X射线衍射图。我们还将我们的方法与类似问题中使用的最新技术进行了比较。这项工作对于设计高通量勘探具有重要意义,其中包括用于电化学系统(例如燃料电池和金属空气电池)的催化剂。










































 京公网安备 11010802027423号
京公网安备 11010802027423号