Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Grandmaster level in StarCraft II using multi-agent reinforcement learning
Nature ( IF 50.5 ) Pub Date : 2019-10-30 , DOI: 10.1038/s41586-019-1724-z Oriol Vinyals 1 , Igor Babuschkin 1 , Wojciech M Czarnecki 1 , Michaël Mathieu 1 , Andrew Dudzik 1 , Junyoung Chung 1 , David H Choi 1 , Richard Powell 1 , Timo Ewalds 1 , Petko Georgiev 1 , Junhyuk Oh 1 , Dan Horgan 1 , Manuel Kroiss 1 , Ivo Danihelka 1 , Aja Huang 1 , Laurent Sifre 1 , Trevor Cai 1 , John P Agapiou 1 , Max Jaderberg 1 , Alexander S Vezhnevets 1 , Rémi Leblond 1 , Tobias Pohlen 1 , Valentin Dalibard 1 , David Budden 1 , Yury Sulsky 1 , James Molloy 1 , Tom L Paine 1 , Caglar Gulcehre 1 , Ziyu Wang 1 , Tobias Pfaff 1 , Yuhuai Wu 1 , Roman Ring 1 , Dani Yogatama 1 , Dario Wünsch 2 , Katrina McKinney 1 , Oliver Smith 1 , Tom Schaul 1 , Timothy Lillicrap 1 , Koray Kavukcuoglu 1 , Demis Hassabis 1 , Chris Apps 1 , David Silver 1
Nature ( IF 50.5 ) Pub Date : 2019-10-30 , DOI: 10.1038/s41586-019-1724-z Oriol Vinyals 1 , Igor Babuschkin 1 , Wojciech M Czarnecki 1 , Michaël Mathieu 1 , Andrew Dudzik 1 , Junyoung Chung 1 , David H Choi 1 , Richard Powell 1 , Timo Ewalds 1 , Petko Georgiev 1 , Junhyuk Oh 1 , Dan Horgan 1 , Manuel Kroiss 1 , Ivo Danihelka 1 , Aja Huang 1 , Laurent Sifre 1 , Trevor Cai 1 , John P Agapiou 1 , Max Jaderberg 1 , Alexander S Vezhnevets 1 , Rémi Leblond 1 , Tobias Pohlen 1 , Valentin Dalibard 1 , David Budden 1 , Yury Sulsky 1 , James Molloy 1 , Tom L Paine 1 , Caglar Gulcehre 1 , Ziyu Wang 1 , Tobias Pfaff 1 , Yuhuai Wu 1 , Roman Ring 1 , Dani Yogatama 1 , Dario Wünsch 2 , Katrina McKinney 1 , Oliver Smith 1 , Tom Schaul 1 , Timothy Lillicrap 1 , Koray Kavukcuoglu 1 , Demis Hassabis 1 , Chris Apps 1 , David Silver 1
Affiliation
|
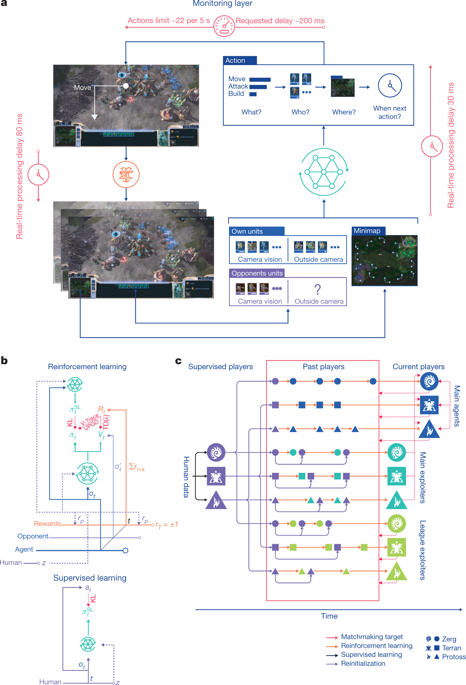
Many real-world applications require artificial agents to compete and coordinate with other agents in complex environments. As a stepping stone to this goal, the domain of StarCraft has emerged as an important challenge for artificial intelligence research, owing to its iconic and enduring status among the most difficult professional esports and its relevance to the real world in terms of its raw complexity and multi-agent challenges. Over the course of a decade and numerous competitions1–3, the strongest agents have simplified important aspects of the game, utilized superhuman capabilities, or employed hand-crafted sub-systems4. Despite these advantages, no previous agent has come close to matching the overall skill of top StarCraft players. We chose to address the challenge of StarCraft using general-purpose learning methods that are in principle applicable to other complex domains: a multi-agent reinforcement learning algorithm that uses data from both human and agent games within a diverse league of continually adapting strategies and counter-strategies, each represented by deep neural networks5,6. We evaluated our agent, AlphaStar, in the full game of StarCraft II, through a series of online games against human players. AlphaStar was rated at Grandmaster level for all three StarCraft races and above 99.8% of officially ranked human players.AlphaStar uses a multi-agent reinforcement learning algorithm and has reached Grandmaster level, ranking among the top 0.2% of human players for the real-time strategy game StarCraft II.
中文翻译:

使用多智能体强化学习的星际争霸 II 中的宗师级别
许多现实世界的应用程序需要人工代理在复杂环境中与其他代理竞争和协调。作为实现这一目标的垫脚石,《星际争霸》领域已成为人工智能研究的一项重要挑战,因为它在最困难的职业电子竞技中具有标志性和持久的地位,并且在其原始复杂性和与现实世界的相关性方面具有重要意义。多智能体挑战。在十年的过程中和无数的比赛 1-3 中,最强大的代理已经简化了游戏的重要方面,利用了超人的能力,或者使用了手工制作的子系统 4。尽管有这些优势,但之前没有任何特工能够与星际争霸顶级玩家的整体技能相媲美。我们选择使用原则上适用于其他复杂领域的通用学习方法来应对星际争霸的挑战:一种多智能体强化学习算法,它使用来自人类和智能体游戏的数据,在不断适应的策略和反击的多样化联盟中-策略,每个都由深度神经网络5,6表示。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。一种多智能体强化学习算法,它使用来自人类和智能体游戏的数据,在不断适应的策略和反策略的多样化联盟中,每一种都由深度神经网络 5,6 表示。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。一种多智能体强化学习算法,它使用来自人类和智能体游戏的数据,在不断适应的策略和反策略的多样化联盟中,每一种都由深度神经网络 5,6 表示。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。
更新日期:2019-10-30
中文翻译:
使用多智能体强化学习的星际争霸 II 中的宗师级别
许多现实世界的应用程序需要人工代理在复杂环境中与其他代理竞争和协调。作为实现这一目标的垫脚石,《星际争霸》领域已成为人工智能研究的一项重要挑战,因为它在最困难的职业电子竞技中具有标志性和持久的地位,并且在其原始复杂性和与现实世界的相关性方面具有重要意义。多智能体挑战。在十年的过程中和无数的比赛 1-3 中,最强大的代理已经简化了游戏的重要方面,利用了超人的能力,或者使用了手工制作的子系统 4。尽管有这些优势,但之前没有任何特工能够与星际争霸顶级玩家的整体技能相媲美。我们选择使用原则上适用于其他复杂领域的通用学习方法来应对星际争霸的挑战:一种多智能体强化学习算法,它使用来自人类和智能体游戏的数据,在不断适应的策略和反击的多样化联盟中-策略,每个都由深度神经网络5,6表示。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。一种多智能体强化学习算法,它使用来自人类和智能体游戏的数据,在不断适应的策略和反策略的多样化联盟中,每一种都由深度神经网络 5,6 表示。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。一种多智能体强化学习算法,它使用来自人类和智能体游戏的数据,在不断适应的策略和反策略的多样化联盟中,每一种都由深度神经网络 5,6 表示。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。我们通过一系列针对人类玩家的在线游戏,在星际争霸 II 的完整游戏中评估了我们的代理 AlphaStar。AlphaStar 在星际争霸的所有三场比赛中均被评为宗师级,官方排名的人类玩家中超过 99.8%。AlphaStar 使用多智能体强化学习算法,已达到宗师级,实时排名前 0.2% 的人类玩家战略游戏星际争霸II。










































 京公网安备 11010802027423号
京公网安备 11010802027423号