当前位置:
X-MOL 学术
›
Biotechnol. J.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Multivariate Data Analysis Methodology to Solve Data Challenges Related to Scale-Up Model Validation and Missing Data on a Micro-Bioreactor System.
Biotechnology Journal ( IF 4.7 ) Pub Date : 2019-11-22 , DOI: 10.1002/biot.201800684 Stephen Goldrick 1, 2 , Viktor Sandner 3 , Matthew Cheeks 2 , Richard Turner 2 , Suzanne S Farid 1 , Graham McCreath 3 , Jarka Glassey 4
Biotechnology Journal ( IF 4.7 ) Pub Date : 2019-11-22 , DOI: 10.1002/biot.201800684 Stephen Goldrick 1, 2 , Viktor Sandner 3 , Matthew Cheeks 2 , Richard Turner 2 , Suzanne S Farid 1 , Graham McCreath 3 , Jarka Glassey 4
Affiliation
|
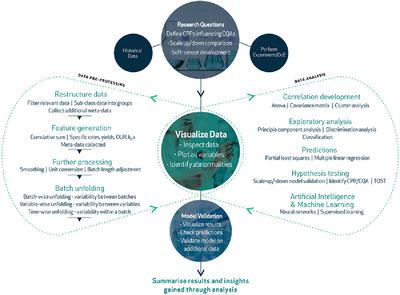
Multivariate data analysis (MVDA) is a highly valuable and significantly underutilized resource in biomanufacturing. It offers the opportunity to enhance understanding and leverage useful information from complex high-dimensional data sets, recorded throughout all stages of therapeutic drug manufacture. To help standardize the application and promote this resource within the biopharmaceutical industry, this paper outlines a novel MVDA methodology describing the necessary steps for efficient and effective data analysis. The MVDA methodology is followed to solve two case studies: a "small data" and a "big data" challenge. In the "small data" example, a large-scale data set is compared to data from a scale-down model. This methodology enables a new quantitative metric for equivalence to be established by combining a two one-sided test with principal component analysis. In the "big data" example, this methodology enables accurate predictions of critical missing data essential to a cloning study performed in the ambr15 system. These predictions are generated by exploiting the underlying relationship between the off-line missing values and the on-line measurements through the generation of a partial least squares model. In summary, the proposed MVDA methodology highlights the importance of data pre-processing, restructuring, and visualization during data analytics to solve complex biopharmaceutical challenges.
中文翻译:

多元数据分析方法论,可以解决与放大模型验证相关的数据挑战以及微型生物反应器系统上的数据丢失问题。
多元数据分析(MVDA)在生物制造中是一种非常有价值的资源,且利用率极低。它提供了机会,可以增进了解并利用来自复杂高维数据集的有用信息,这些数据是在治疗药物制造的所有阶段中记录的。为了帮助标准化应用程序并在生物制药行业中推广这种资源,本文概述了一种新颖的MVDA方法,该方法描述了有效而有效的数据分析的必要步骤。遵循MVDA方法来解决两个案例研究:“小数据”和“大数据”挑战。在“小数据”示例中,将大型数据集与按比例缩小模型的数据进行比较。该方法通过将两个单侧测试与主成分分析相结合,可以建立新的等效定量指标。在“大数据”示例中,此方法可对ambr15系统中进行的克隆研究必不可少的关键缺失数据进行准确预测。通过利用偏最小二乘模型的生成来利用离线缺失值与在线测量之间的潜在关系来生成这些预测。总之,提出的MVDA方法论突出了在数据分析过程中进行数据预处理,重组和可视化以解决复杂的生物制药挑战的重要性。这种方法可以准确预测关键缺失数据,这些数据对于在ambr15系统中进行的克隆研究必不可少。通过利用偏最小二乘模型的生成来利用离线缺失值与在线测量之间的潜在关系来生成这些预测。总之,提出的MVDA方法论突出了在数据分析过程中进行数据预处理,重组和可视化以解决复杂的生物制药挑战的重要性。这种方法可以准确预测关键缺失数据,这些数据对于在ambr15系统中进行的克隆研究必不可少。通过利用偏最小二乘模型的生成来利用离线缺失值与在线测量之间的潜在关系来生成这些预测。总之,提出的MVDA方法论突出了在数据分析过程中进行数据预处理,重组和可视化以解决复杂的生物制药挑战的重要性。
更新日期:2019-11-22
中文翻译:
多元数据分析方法论,可以解决与放大模型验证相关的数据挑战以及微型生物反应器系统上的数据丢失问题。
多元数据分析(MVDA)在生物制造中是一种非常有价值的资源,且利用率极低。它提供了机会,可以增进了解并利用来自复杂高维数据集的有用信息,这些数据是在治疗药物制造的所有阶段中记录的。为了帮助标准化应用程序并在生物制药行业中推广这种资源,本文概述了一种新颖的MVDA方法,该方法描述了有效而有效的数据分析的必要步骤。遵循MVDA方法来解决两个案例研究:“小数据”和“大数据”挑战。在“小数据”示例中,将大型数据集与按比例缩小模型的数据进行比较。该方法通过将两个单侧测试与主成分分析相结合,可以建立新的等效定量指标。在“大数据”示例中,此方法可对ambr15系统中进行的克隆研究必不可少的关键缺失数据进行准确预测。通过利用偏最小二乘模型的生成来利用离线缺失值与在线测量之间的潜在关系来生成这些预测。总之,提出的MVDA方法论突出了在数据分析过程中进行数据预处理,重组和可视化以解决复杂的生物制药挑战的重要性。这种方法可以准确预测关键缺失数据,这些数据对于在ambr15系统中进行的克隆研究必不可少。通过利用偏最小二乘模型的生成来利用离线缺失值与在线测量之间的潜在关系来生成这些预测。总之,提出的MVDA方法论突出了在数据分析过程中进行数据预处理,重组和可视化以解决复杂的生物制药挑战的重要性。这种方法可以准确预测关键缺失数据,这些数据对于在ambr15系统中进行的克隆研究必不可少。通过利用偏最小二乘模型的生成来利用离线缺失值与在线测量之间的潜在关系来生成这些预测。总之,提出的MVDA方法论突出了在数据分析过程中进行数据预处理,重组和可视化以解决复杂的生物制药挑战的重要性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号