npj Quantum Information ( IF 7.6 ) Pub Date : 2019-10-08 , DOI: 10.1038/s41534-019-0201-8 Xiao-Ming Zhang , Zezhu Wei , Raza Asad , Xu-Chen Yang , Xin Wang
|
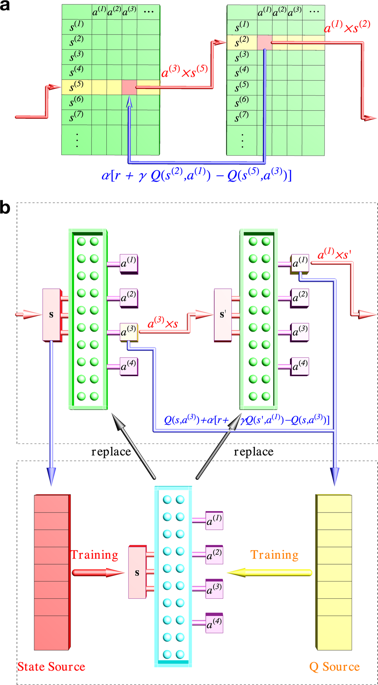
Reinforcement learning has been widely used in many problems, including quantum control of qubits. However, such problems can, at the same time, be solved by traditional, non-machine-learning methods, such as stochastic gradient descent and Krotov algorithms, and it remains unclear which one is most suitable when the control has specific constraints. In this work, we perform a comparative study on the efficacy of three reinforcement learning algorithms: tabular Q-learning, deep Q-learning, and policy gradient, as well as two non-machine-learning methods: stochastic gradient descent and Krotov algorithms, in the problem of preparing a desired quantum state. We found that overall, the deep Q-learning and policy gradient algorithms outperform others when the problem is discretized, e.g. allowing discrete values of control, and when the problem scales up. The reinforcement learning algorithms can also adaptively reduce the complexity of the control sequences, shortening the operation time and improving the fidelity. Our comparison provides insights into the suitability of reinforcement learning in quantum control problems.
中文翻译:
强化学习什么时候在量子控制中脱颖而出?国家准备的比较研究
强化学习已被广泛用于许多问题中,包括量子位的量子控制。但是,这些问题可以同时通过传统的非机器学习方法(例如,随机梯度下降法和Krotov算法)解决,并且尚不清楚当控制具有特定约束时,哪种方法最合适。在这项工作中,我们对三种强化学习算法的有效性进行了比较研究:表格Q学习,深度Q学习和策略梯度,以及两种非机器学习方法:随机梯度下降和Krotov算法,在准备所需的量子态的问题上。我们发现总体上,当问题离散化时,例如允许离散控制值,以及问题何时扩大。强化学习算法还可以自适应地降低控制序列的复杂性,缩短操作时间并提高保真度。我们的比较为增强学习在量子控制问题中的适用性提供了见识。


























 京公网安备 11010802027423号
京公网安备 11010802027423号