npj Digital Medicine ( IF 12.4 ) Pub Date : 2019-10-01 , DOI: 10.1038/s41746-019-0170-5 Ari Z Klein 1 , Abeed Sarker 2 , Davy Weissenbacher 1 , Graciela Gonzalez-Hernandez 1
|
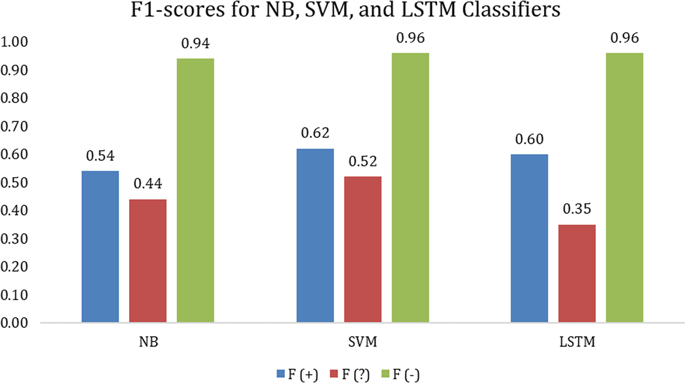
Social media has recently been used to identify and study a small cohort of Twitter users whose pregnancies with birth defect outcomes—the leading cause of infant mortality—could be observed via their publicly available tweets. In this study, we exploit social media on a larger scale by developing natural language processing (NLP) methods to automatically detect, among thousands of users, a cohort of mothers reporting that their child has a birth defect. We used 22,999 annotated tweets to train and evaluate supervised machine learning algorithms—feature-engineered and deep learning-based classifiers—that automatically distinguish tweets referring to the user’s pregnancy outcome from tweets that merely mention birth defects. Because 90% of the tweets merely mention birth defects, we experimented with under-sampling and over-sampling approaches to address this class imbalance. An SVM classifier achieved the best performance for the two positive classes: an F1-score of 0.65 for the “defect” class and 0.51 for the “possible defect” class. We deployed the classifier on 20,457 unlabeled tweets that mention birth defects, which helped identify 542 additional users for potential inclusion in our cohort. Contributions of this study include (1) NLP methods for automatically detecting tweets by users reporting their birth defect outcomes, (2) findings that an SVM classifier can outperform a deep neural network-based classifier for highly imbalanced social media data, (3) evidence that automatic classification can be used to identify additional users for potential inclusion in our cohort, and (4) a publicly available corpus for training and evaluating supervised machine learning algorithms.
中文翻译:
致力于扩展 Twitter 以进行出生缺陷的数字流行病学研究
最近,社交媒体被用来识别和研究一小群推特用户,他们的怀孕是否患有先天缺陷(婴儿死亡率的主要原因),可以通过他们公开的推文观察到。在这项研究中,我们通过开发自然语言处理(NLP)方法来更大规模地利用社交媒体,以在数千名用户中自动检测一组报告其孩子有先天缺陷的母亲。我们使用 22,999 条带注释的推文来训练和评估监督机器学习算法(特征工程和基于深度学习的分类器),该算法会自动区分涉及用户怀孕结果的推文和仅提及出生缺陷的推文。由于 90% 的推文仅提及出生缺陷,因此我们尝试了欠采样和过采样方法来解决此类不平衡问题。 SVM 分类器在两个正类别中实现了最佳性能:“缺陷”类别的 F 1分数为 0.65,“可能缺陷”类别的 F 1 分数为 0.51。我们在 20,457 条提及出生缺陷的未标记推文上部署了分类器,这有助于识别出另外 542 名可能纳入我们队列的用户。这项研究的贡献包括 (1) 自动检测用户报告出生缺陷结果的推文的 NLP 方法,(2) 研究发现,对于高度不平衡的社交媒体数据,SVM 分类器可以优于基于深度神经网络的分类器,(3) 证据自动分类可用于识别可能包含在我们队列中的其他用户,以及(4)用于训练和评估监督机器学习算法的公开语料库。








































 京公网安备 11010802027423号
京公网安备 11010802027423号