当前位置:
X-MOL 学术
›
Environ. Sci. Technol. Lett.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Using Chemical Transport Model Predictions To Improve Exposure Assessment of PM2.5 Constituents
Environmental Science & Technology Letters ( IF 8.9 ) Pub Date : 2019-08-05 , DOI: 10.1021/acs.estlett.9b00396 Jianlin Hu 1 , Bart Ostro 2 , Hongliang Zhang 3 , Qi Ying 4 , Michael J. Kleeman 5
Environmental Science & Technology Letters ( IF 8.9 ) Pub Date : 2019-08-05 , DOI: 10.1021/acs.estlett.9b00396 Jianlin Hu 1 , Bart Ostro 2 , Hongliang Zhang 3 , Qi Ying 4 , Michael J. Kleeman 5
Affiliation
|
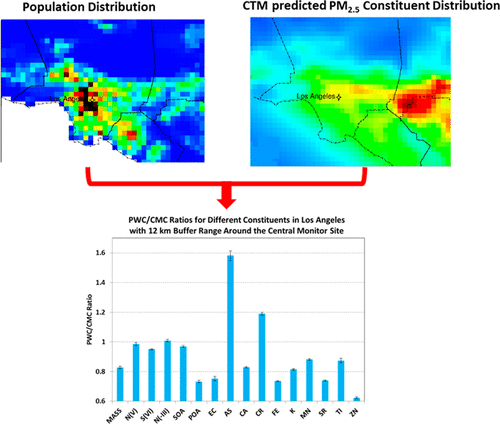
Air pollution health-effect studies commonly use central monitor concentrations (CMCs) of airborne fine particulate matter (PM2.5) to represent population exposure near the monitoring sites. The spatial distribution of PM2.5 constituents is presumed to be the same and is well-represented by the CMC. Here we apply chemical transport models in California and show that the population-weighted concentrations (PWCs) of secondary PM2.5 constituents within the 12 km buffer zone are within ±20% of the respective CMC values, but the PWCs of primary PM2.5 constituents differ from the CMC values by −40 to +60%. The appropriate CMC representative distance varies significantly in different cities due to the unique combination of population distribution, emissions patterns, and meteorology at each location. We conclude that exposure misclassification can be significant if the same representative distance is assumed for multiple CMC PM2.5 constituents across all sites in a single air pollution epidemiology study that has a large spatial and temporal range. This misclassification will increase the variance around the effect estimate and therefore reduce the likelihood of finding a statistically significant effect.
中文翻译:

使用化学传输模型预测来改进PM2.5成分的暴露评估
空气污染健康影响研究通常使用中央监测器中的空气传播细颗粒物(PM 2.5)浓度(CMC )来表示监测地点附近的人口暴露。假定PM 2.5成分的空间分布是相同的,并且由CMC很好地表示。在这里,我们使用加利福尼亚州的化学迁移模型,表明在12 km缓冲区内次级PM 2.5成分的人口加权浓度(PWC)在各自CMC值的±20%之内,但是初级PM 2.5的PWC成分与CMC值的差值为-40至+ 60%。由于每个位置的人口分布,排放模式和气象学的独特组合,不同城市中适当的CMC代表距离差异很大。我们得出的结论是,如果在单个具有较大时空范围的空气污染流行病学研究中,假设所有站点上多个CMC PM 2.5成分的代表距离相同,则暴露的分类错误会很明显。这种错误分类将增加效果估计值周围的方差,因此会降低找到具有统计学意义的效果的可能性。
更新日期:2019-08-05
中文翻译:
使用化学传输模型预测来改进PM2.5成分的暴露评估
空气污染健康影响研究通常使用中央监测器中的空气传播细颗粒物(PM 2.5)浓度(CMC )来表示监测地点附近的人口暴露。假定PM 2.5成分的空间分布是相同的,并且由CMC很好地表示。在这里,我们使用加利福尼亚州的化学迁移模型,表明在12 km缓冲区内次级PM 2.5成分的人口加权浓度(PWC)在各自CMC值的±20%之内,但是初级PM 2.5的PWC成分与CMC值的差值为-40至+ 60%。由于每个位置的人口分布,排放模式和气象学的独特组合,不同城市中适当的CMC代表距离差异很大。我们得出的结论是,如果在单个具有较大时空范围的空气污染流行病学研究中,假设所有站点上多个CMC PM 2.5成分的代表距离相同,则暴露的分类错误会很明显。这种错误分类将增加效果估计值周围的方差,因此会降低找到具有统计学意义的效果的可能性。










































 京公网安备 11010802027423号
京公网安备 11010802027423号