npj Computational Materials ( IF 9.4 ) Pub Date : 2019-07-19 , DOI: 10.1038/s41524-019-0213-0 Sebastian E. Ament , Helge S. Stein , Dan Guevarra , Lan Zhou , Joel A. Haber , David A. Boyd , Mitsutaro Umehara , John M. Gregoire , Carla P. Gomes
|
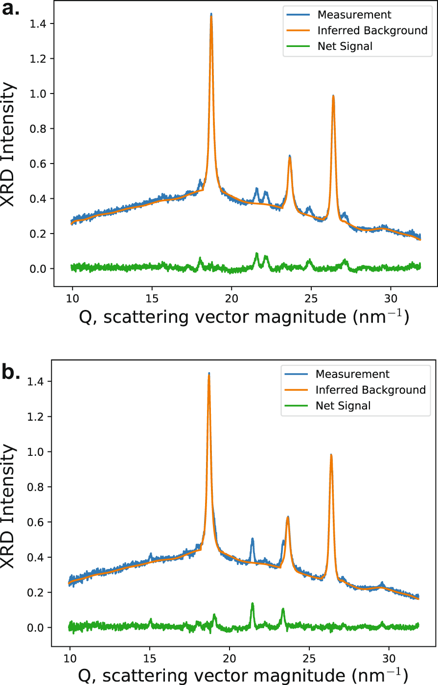
Automated experimentation has yielded data acquisition rates that supersede human processing capabilities. Artificial Intelligence offers new possibilities for automating data interpretation to generate large, high-quality datasets. Background subtraction is a long-standing challenge, particularly in settings where multiple sources of the background signal coexist, and automatic extraction of signals of interest from measured signals accelerates data interpretation. Herein, we present an unsupervised probabilistic learning approach that analyzes large data collections to identify multiple background sources and establish the probability that any given data point contains a signal of interest. The approach is demonstrated on X-ray diffraction and Raman spectroscopy data and is suitable to any type of data where the signal of interest is a positive addition to the background signals. While the model can incorporate prior knowledge, it does not require knowledge of the signals since the shapes of the background signals, the noise levels, and the signal of interest are simultaneously learned via a probabilistic matrix factorization framework. Automated identification of interpretable signals by unsupervised probabilistic learning avoids the injection of human bias and expedites signal extraction in large datasets, a transformative capability with many applications in the physical sciences and beyond.
中文翻译:
多成分背景学习可自动执行光谱数据的信号检测
自动化实验产生的数据采集速率已取代了人类的处理能力。人工智能为自动进行数据解释以生成大型高质量数据集提供了新的可能性。背景减法是一个长期的挑战,特别是在背景信号的多个源共存的环境中,从测量信号中自动提取感兴趣的信号会加速数据解释。在这里,我们提出了一种无监督的概率学习方法,该方法分析大型数据集以识别多个背景源,并确定任何给定数据点包含感兴趣信号的概率。该方法在X射线衍射和拉曼光谱数据上得到了证明,并且适用于任何类型的数据,其中感兴趣的信号是对背景信号的正相加。尽管模型可以包含先验知识,但由于背景信号的形状,噪声水平和感兴趣的信号是通过概率矩阵分解框架同时学习的,因此不需要信号的知识。通过无监督的概率学习自动识别可解释的信号,避免了在大型数据集中注入人为偏差并加快了信号提取的速度,这是一种在物理科学及其他领域具有许多应用的转换能力。它不需要信号的知识,因为背景信号的形状,噪声水平和感兴趣的信号是通过概率矩阵分解框架同时学习的。通过无监督的概率学习自动识别可解释的信号,避免了在大型数据集中注入人为偏差并加快了信号提取的速度,这是一种在物理科学及其他领域具有许多应用的转换能力。它不需要信号的知识,因为背景信号的形状,噪声水平和感兴趣的信号是通过概率矩阵分解框架同时学习的。通过无监督的概率学习自动识别可解释的信号,避免了在大型数据集中注入人为偏差并加快了信号提取的速度,这是一种在物理科学及其他领域具有许多应用的转换能力。








































 京公网安备 11010802027423号
京公网安备 11010802027423号