Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
The influence of rewards on (sub-)optimal interleaving.
PLOS ONE ( IF 3.7 ) Pub Date : 2019-03-18 , DOI: 10.1371/journal.pone.0214027 Christian P Janssen 1 , Emma Everaert 1 , Heleen M A Hendriksen 1 , Ghislaine L Mensing 1 , Laura J Tigchelaar 1 , Hendrik Nunner 1
PLOS ONE ( IF 3.7 ) Pub Date : 2019-03-18 , DOI: 10.1371/journal.pone.0214027 Christian P Janssen 1 , Emma Everaert 1 , Heleen M A Hendriksen 1 , Ghislaine L Mensing 1 , Laura J Tigchelaar 1 , Hendrik Nunner 1
Affiliation
|
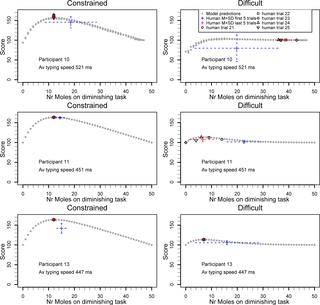
We investigate how the rewards of individual tasks dictate a priori how easy it is to interleave two discrete tasks efficiently, and whether people then interleave efficiently. Previous research found that people vary in their ability to interleave efficiently. Less attention has been given to whether it was realistic to expect efficient interleaving, given the reward rate of each of the involved tasks. Using a simulation model, we demonstrate how the rewards of individual tasks lead to different dual-task interleaving scenarios. We identify three unique dual-task scenarios. In easy scenarios, many strategies for time division between tasks can achieve optimal performance. This gives great opportunity to optimize performance, but also leads to variation in the applied strategies due to a lack of pressure to settle on a small set of optimal strategies. In difficult scenarios, the optimal strategy is hard to identify, therefore giving little opportunity to optimize. Finally, constrained scenarios have a well-defined prediction of the optimal strategy. It gives a narrow prediction, which limits the options to achieve optimal scores, yet given the structure people are able to optimize their strategies. These scenarios are therefore best to test people's general capability of optimizing interleaving. We report three empirical studies that test these hypotheses. In each study, participants interleave between two identical discrete tasks, that differ only in the underlying reward functions and the combined result (easy, difficult, or constrained scenario). Empirical results match the theoretical pattern as predicted by simulation models. Implications for theory and practice are discussed.
中文翻译:

奖励对(次)最优交织的影响。
我们研究了单个任务的收益如何指示先验地有效地交错两个离散任务有多容易,以及人们是否然后有效地交错。先前的研究发现,人们有效交织的能力各不相同。考虑到每个涉及的任务的奖励率,人们很少关注期望有效的交织是否现实。使用模拟模型,我们演示了单个任务的奖励如何导致不同的双任务交错方案。我们确定了三种独特的双重任务方案。在简单的情况下,许多任务之间的时分策略可以达到最佳性能。这为优化性能提供了绝佳的机会,但由于缺乏解决一小套最佳策略的压力,也会导致所应用策略的变化。在困难的情况下,最佳策略很难确定,因此几乎没有机会进行优化。最后,受约束的方案具有最佳策略的明确定义的预测。它给出了一个狭窄的预测,这限制了获得最佳分数的选择,但是考虑到人们能够优化其策略的结构。因此,这些方案最适合测试人们优化交错的一般能力。我们报告了三个检验这些假设的实证研究。在每个研究中,参与者在两个相同的离散任务之间交织在一起,这些任务仅在基本的奖励功能和组合结果(简单,困难或受限的场景)方面有所不同。经验结果与仿真模型预测的理论模式相符。讨论了对理论和实践的影响。
更新日期:2019-03-19
中文翻译:
奖励对(次)最优交织的影响。
我们研究了单个任务的收益如何指示先验地有效地交错两个离散任务有多容易,以及人们是否然后有效地交错。先前的研究发现,人们有效交织的能力各不相同。考虑到每个涉及的任务的奖励率,人们很少关注期望有效的交织是否现实。使用模拟模型,我们演示了单个任务的奖励如何导致不同的双任务交错方案。我们确定了三种独特的双重任务方案。在简单的情况下,许多任务之间的时分策略可以达到最佳性能。这为优化性能提供了绝佳的机会,但由于缺乏解决一小套最佳策略的压力,也会导致所应用策略的变化。在困难的情况下,最佳策略很难确定,因此几乎没有机会进行优化。最后,受约束的方案具有最佳策略的明确定义的预测。它给出了一个狭窄的预测,这限制了获得最佳分数的选择,但是考虑到人们能够优化其策略的结构。因此,这些方案最适合测试人们优化交错的一般能力。我们报告了三个检验这些假设的实证研究。在每个研究中,参与者在两个相同的离散任务之间交织在一起,这些任务仅在基本的奖励功能和组合结果(简单,困难或受限的场景)方面有所不同。经验结果与仿真模型预测的理论模式相符。讨论了对理论和实践的影响。


























 京公网安备 11010802027423号
京公网安备 11010802027423号