International Journal of Computer Vision ( IF 19.5 ) Pub Date : 2024-04-24 , DOI: 10.1007/s11263-024-02026-6 Valentin Gabeff , Marc Rußwurm , Devis Tuia , Alexander Mathis
|
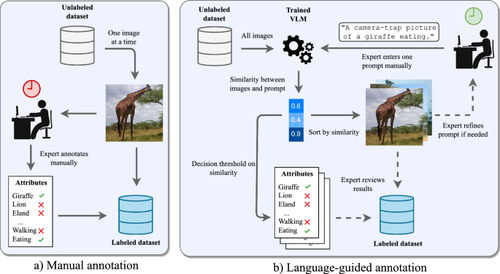
Wildlife observation with camera traps has great potential for ethology and ecology, as it gathers data non-invasively in an automated way. However, camera traps produce large amounts of uncurated data, which is time-consuming to annotate. Existing methods to label these data automatically commonly use a fixed pre-defined set of distinctive classes and require many labeled examples per class to be trained. Moreover, the attributes of interest are sometimes rare and difficult to find in large data collections. Large pretrained vision-language models, such as contrastive language image pretraining (CLIP), offer great promises to facilitate the annotation process of camera-trap data. Images can be described with greater detail, the set of classes is not fixed and can be extensible on demand and pretrained models can help to retrieve rare samples. In this work, we explore the potential of CLIP to retrieve images according to environmental and ecological attributes. We create WildCLIP by fine-tuning CLIP on wildlife camera-trap images and to further increase its flexibility, we add an adapter module to better expand to novel attributes in a few-shot manner. We quantify WildCLIP’s performance and show that it can retrieve novel attributes in the Snapshot Serengeti dataset. Our findings outline new opportunities to facilitate annotation processes with complex and multi-attribute captions. The code is available at https://github.com/amathislab/wildclip.
中文翻译:
WildCLIP:使用领域适应视觉语言模型从相机陷阱数据中检索场景和动物属性
使用相机陷阱观察野生动物在行为学和生态学方面具有巨大潜力,因为它以自动化方式非侵入性地收集数据。然而,相机陷阱会产生大量未经整理的数据,注释起来非常耗时。自动标记这些数据的现有方法通常使用一组固定的预定义的独特类,并且需要对每个类进行许多标记示例进行训练。此外,感兴趣的属性有时很少见,并且很难在大型数据集中找到。大型预训练视觉语言模型,例如对比语言图像预训练(CLIP),为促进相机陷阱数据的注释过程提供了巨大的希望。图像可以更详细地描述,类集不是固定的,可以根据需要扩展,预训练模型可以帮助检索稀有样本。在这项工作中,我们探索了 CLIP 根据环境和生态属性检索图像的潜力。我们通过对野生动物相机陷阱图像上的 CLIP 进行微调来创建 WildCLIP,为了进一步提高其灵活性,我们添加了一个适配器模块,以便以几次拍摄的方式更好地扩展到新的属性。我们量化了 WildCLIP 的性能,并表明它可以检索塞伦盖蒂快照数据集中的新属性。我们的研究结果概述了利用复杂和多属性标题促进注释过程的新机会。该代码可在 https://github.com/amathislab/wildclip 获取。


























 京公网安备 11010802027423号
京公网安备 11010802027423号