当前位置:
X-MOL 学术
›
J. Alloys Compd.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Improving the performance of machine learning model predicting phase and crystal structure of high entropy alloys by the synthetic minority oversampling technique
Journal of Alloys and Compounds ( IF 6.2 ) Pub Date : 2024-04-16 , DOI: 10.1016/j.jallcom.2024.174494 K Hareharen , T Panneerselvam , R Raj Mohan
Journal of Alloys and Compounds ( IF 6.2 ) Pub Date : 2024-04-16 , DOI: 10.1016/j.jallcom.2024.174494 K Hareharen , T Panneerselvam , R Raj Mohan
|
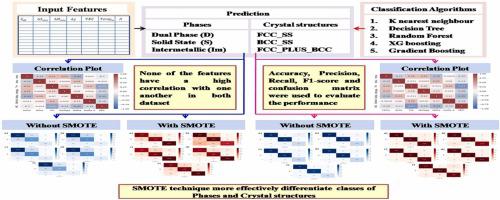
It is critical to select the suitable integration of elements that has an influence on phase formation when selecting the proper High Entropy Alloys (HEAs) with desired qualities. Machine Learning (ML) models were used to predict the phase and crystal structure of HEAs in this study. Trained on extensive experimental datasets, the set of input characteristics includes Atomic size difference, Mixing Enthalpy, Mixing Entropy, Valence Electron concentration, Electronegativity difference, and Average Melting Temperature. The phase is divided into three categories: Solid solution (S), Dual phase (D), and Intermetallic (Im). Crystal structure classifications include BCC, FCC, and FCC+BCC. For phase and crystal structure prediction, five ML algorithms were used: Decision Tree (DT), K Nearest Neighbour (KNN), Random Forest (RF), Gradient Boosting (GB) and eXtreme Gradient Boosting (XG Boosting), The classification of the HEAs phase has been predicted with great accuracy using an XG Boosting (80 %) and Random Forest exhibits the highest accuracy (94 %) for crystal structure prediction when model is trained on an experimental dataset. Even though the ML model predicts the classes with a better degree of accuracy (>80 %), the F1 value of each class varies more dramatically. This issue has arisen as a result of an imbalance in the dataset's class distribution. To boost performance, this work uses an ML model in conjunction with the Synthetic Minority Oversampling Technique (SMOTE). According to this approach, XG boosting identified the crystal structure with 93 % accuracy and predicted the phase of HEAs with 84 % accuracy. Additionally, it has been noted that each class's F1 score improved and the difference between them was reduced after using the SMOTE technique. It is evident that the SMOTE approach has improved the ML model's ability to differentiate between the various classes.
中文翻译:

通过合成少数过采样技术提高机器学习模型预测高熵合金相和晶体结构的性能
在选择具有所需品质的合适高熵合金 (HEA) 时,选择对相形成有影响的元素的适当组合至关重要。本研究中使用机器学习 (ML) 模型来预测 HEA 的相和晶体结构。该组输入特征经过大量实验数据集的训练,包括原子尺寸差、混合熵、混合熵、价电子浓度、电负性差和平均熔化温度。该相分为三类:固溶体 (S)、双相 (D) 和金属间化合物 (Im)。晶体结构分类包括 BCC、FCC 和 FCC+BCC。对于相和晶体结构预测,使用了五种 ML 算法:决策树 (DT)、K 最近邻 (KNN)、随机森林 (RF)、梯度提升 (GB) 和极限梯度提升 (XG Boosting)。使用 XG Boosting (80%) 可以非常准确地预测 HEAs 相,当在实验数据集上训练模型时,随机森林在晶体结构预测方面表现出最高的准确度 (94%)。尽管 ML 模型以更高的准确度 (>80%) 预测类别,但每个类别的 F1 值变化更大。这个问题是由于数据集的类别分布不平衡而出现的。为了提高性能,这项工作将 ML 模型与合成少数过采样技术 (SMOTE) 结合使用。根据这种方法,XG boosting 识别晶体结构的准确度为 93%,预测 HEA 的相位的准确度为 84%。此外,值得注意的是,使用 SMOTE 技术后,每个班级的 F1 分数都有所提高,并且它们之间的差异也有所缩小。显然,SMOTE 方法提高了 ML 模型区分不同类别的能力。
更新日期:2024-04-16
中文翻译:
通过合成少数过采样技术提高机器学习模型预测高熵合金相和晶体结构的性能
在选择具有所需品质的合适高熵合金 (HEA) 时,选择对相形成有影响的元素的适当组合至关重要。本研究中使用机器学习 (ML) 模型来预测 HEA 的相和晶体结构。该组输入特征经过大量实验数据集的训练,包括原子尺寸差、混合熵、混合熵、价电子浓度、电负性差和平均熔化温度。该相分为三类:固溶体 (S)、双相 (D) 和金属间化合物 (Im)。晶体结构分类包括 BCC、FCC 和 FCC+BCC。对于相和晶体结构预测,使用了五种 ML 算法:决策树 (DT)、K 最近邻 (KNN)、随机森林 (RF)、梯度提升 (GB) 和极限梯度提升 (XG Boosting)。使用 XG Boosting (80%) 可以非常准确地预测 HEAs 相,当在实验数据集上训练模型时,随机森林在晶体结构预测方面表现出最高的准确度 (94%)。尽管 ML 模型以更高的准确度 (>80%) 预测类别,但每个类别的 F1 值变化更大。这个问题是由于数据集的类别分布不平衡而出现的。为了提高性能,这项工作将 ML 模型与合成少数过采样技术 (SMOTE) 结合使用。根据这种方法,XG boosting 识别晶体结构的准确度为 93%,预测 HEA 的相位的准确度为 84%。此外,值得注意的是,使用 SMOTE 技术后,每个班级的 F1 分数都有所提高,并且它们之间的差异也有所缩小。显然,SMOTE 方法提高了 ML 模型区分不同类别的能力。


























 京公网安备 11010802027423号
京公网安备 11010802027423号