Complex & Intelligent Systems ( IF 5.8 ) Pub Date : 2024-03-20 , DOI: 10.1007/s40747-024-01394-3 Guanpeng Zuo , Chenlu Zhang , Zhe Zheng , Wu Zhang , Ruiqing Wang , Jingqi Lu , Xiu Jin , Zhaohui Jiang , Yuan Rao
|
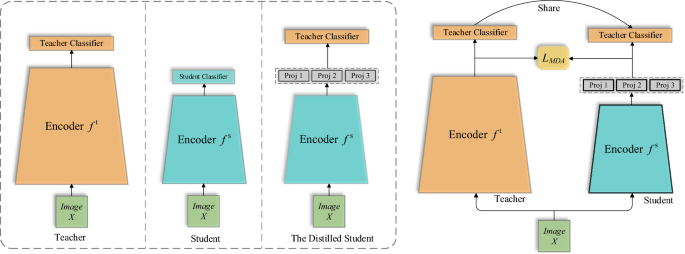
Knowledge distillation can transfer the knowledge from the pre-trained teacher model to the student model, thus effectively accomplishing model compression. Previous studies have carefully crafted knowledge representation, targeting loss function design, and distillation location selection, but there have been few studies on the role of classifiers in distillation. Previous experiences have shown that the final classifier of the model has an essential role in making inferences, so this paper attempts to narrow the gap in performance between models by having the student model directly use the classifier of the teacher model for the final inference, which requires an additional projector to help match features of the student encoder with the teacher's classifier. However, a single projector cannot fully align the features, and integrating multiple projectors may result in better performance. Considering the balance between projector size and performance, through experiments, we obtain the size of projectors for different network combinations and propose a simple method for projector integration. In this way, the student model undergoes feature projection and then uses the classifiers of the teacher model for inference, obtaining a similar performance to the teacher model. Through extensive experiments on the CIFAR-100 and Tiny-ImageNet datasets, we show that our approach applies to various teacher–student frameworks simply and effectively.
中文翻译:
基于投影仪集成和分类器共享的知识蒸馏
知识蒸馏可以将知识从预先训练的教师模型转移到学生模型中,从而有效地完成模型压缩。先前的研究精心设计了知识表示、目标损失函数设计和蒸馏位置选择,但很少有关于分类器在蒸馏中的作用的研究。以往的经验表明,模型最终的分类器对于推理有着至关重要的作用,因此本文尝试通过让学生模型直接使用教师模型的分类器进行最终推理来缩小模型之间的性能差距。需要额外的投影仪来帮助将学生编码器的功能与教师的分类器进行匹配。然而,单台投影仪无法完全对齐功能,集成多台投影仪可能会带来更好的性能。考虑到投影仪尺寸和性能之间的平衡,通过实验,我们获得了不同网络组合下投影仪的尺寸,并提出了一种简单的投影仪集成方法。这样,学生模型经过特征投影,然后使用教师模型的分类器进行推理,获得与教师模型相似的性能。通过对 CIFAR-100 和 Tiny-ImageNet 数据集的大量实验,我们表明我们的方法简单有效地适用于各种师生框架。


























 京公网安备 11010802027423号
京公网安备 11010802027423号