当前位置:
X-MOL 学术
›
J. Biomed. Inform.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Creating a computer assisted ICD coding system: Performance metric choice and use of the ICD hierarchy
Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2024-03-01 , DOI: 10.1016/j.jbi.2024.104617 Quentin Marcou , Laure Berti-Equille , Noël Novelli
Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2024-03-01 , DOI: 10.1016/j.jbi.2024.104617 Quentin Marcou , Laure Berti-Equille , Noël Novelli
|
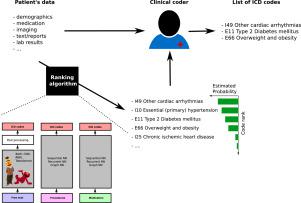
Machine learning methods hold the promise of leveraging available data and generating higher-quality data while alleviating the data collection burden on healthcare professionals. International Classification of Diseases (ICD) diagnoses data, collected globally for billing and epidemiological purposes, represents a valuable source of structured information. However, ICD coding is a challenging task. While numerous previous studies reported promising results in automatic ICD classification, they often describe input data specific model architectures, that are heterogeneously evaluated with different performance metrics and ICD code subsets. We conduct comprehensive experiments using the MIMIC-III clinical database, mapped to the OMOP data model. Our evaluations encompass various performance metrics, alongside investigations into multitask, hierarchical, and imbalanced learning for neural networks. We introduce a novel metric, ▪ , tailored to the ICD coding task, which offers interpretable insights for healthcare informatics practitioners, aiding them in assessing the quality of assisted coding systems. Our findings highlight that selectively cherry-picking ICD codes diminish retrieval performance without performance improvement over the selected subset. We show that optimizing for metrics such as NDCG and AUPRC outperforms traditional F1-based metrics in ranking performance. We observe that Neural Network training on different ICD levels simultaneously offers minor benefits for ranking and significant runtime gains. However, our models do not derive benefits from hierarchical or class imbalance correction techniques for ICD code retrieval. This study offers valuable insights for researchers and healthcare practitioners interested in developing and evaluating CAC systems. Using a straightforward sequential neural network model, we confirm that medical prescriptions are a rich data source for CAC systems, providing competitive retrieval capabilities for a fraction of the computational load compared to text-based models. Our study underscores the importance of metric selection and challenges existing practices related to ICD code sub-setting for model training and evaluation.
中文翻译:

创建计算机辅助 ICD 编码系统:ICD 层次结构的性能指标选择和使用
机器学习方法有望利用可用数据并生成更高质量的数据,同时减轻医疗保健专业人员的数据收集负担。国际疾病分类 (ICD) 诊断数据在全球范围内收集用于计费和流行病学目的,是结构化信息的宝贵来源。然而,ICD 编码是一项具有挑战性的任务。虽然之前的许多研究报告了自动 ICD 分类的有希望的结果,但它们通常描述输入数据特定的模型架构,这些模型架构使用不同的性能指标和 ICD 代码子集进行异构评估。我们使用映射到 OMOP 数据模型的 MIMIC-III 临床数据库进行全面的实验。我们的评估涵盖各种性能指标,以及对神经网络的多任务、分层和不平衡学习的调查。我们引入了一种针对 ICD 编码任务量身定制的新颖指标,为医疗保健信息学从业人员提供可解释的见解,帮助他们评估辅助编码系统的质量。我们的研究结果强调,选择性挑选 ICD 代码会降低检索性能,而不会提高所选子集的性能。我们表明,优化 NDCG 和 AUPRC 等指标在排名性能方面优于传统的基于 F1 的指标。我们观察到,不同 ICD 级别的神经网络训练同时为排名带来了微小的好处,并带来了显着的运行时间增益。然而,我们的模型并没有从 ICD 代码检索的分层或类别不平衡校正技术中获益。这项研究为有兴趣开发和评估 CAC 系统的研究人员和医疗保健从业者提供了宝贵的见解。使用简单的顺序神经网络模型,我们确认医疗处方是 CAC 系统的丰富数据源,与基于文本的模型相比,其计算负载的一小部分提供了有竞争力的检索能力。我们的研究强调了指标选择的重要性,并对模型训练和评估的 ICD 代码子设置相关的现有实践提出了挑战。
更新日期:2024-03-01
中文翻译:
创建计算机辅助 ICD 编码系统:ICD 层次结构的性能指标选择和使用
机器学习方法有望利用可用数据并生成更高质量的数据,同时减轻医疗保健专业人员的数据收集负担。国际疾病分类 (ICD) 诊断数据在全球范围内收集用于计费和流行病学目的,是结构化信息的宝贵来源。然而,ICD 编码是一项具有挑战性的任务。虽然之前的许多研究报告了自动 ICD 分类的有希望的结果,但它们通常描述输入数据特定的模型架构,这些模型架构使用不同的性能指标和 ICD 代码子集进行异构评估。我们使用映射到 OMOP 数据模型的 MIMIC-III 临床数据库进行全面的实验。我们的评估涵盖各种性能指标,以及对神经网络的多任务、分层和不平衡学习的调查。我们引入了一种针对 ICD 编码任务量身定制的新颖指标,为医疗保健信息学从业人员提供可解释的见解,帮助他们评估辅助编码系统的质量。我们的研究结果强调,选择性挑选 ICD 代码会降低检索性能,而不会提高所选子集的性能。我们表明,优化 NDCG 和 AUPRC 等指标在排名性能方面优于传统的基于 F1 的指标。我们观察到,不同 ICD 级别的神经网络训练同时为排名带来了微小的好处,并带来了显着的运行时间增益。然而,我们的模型并没有从 ICD 代码检索的分层或类别不平衡校正技术中获益。这项研究为有兴趣开发和评估 CAC 系统的研究人员和医疗保健从业者提供了宝贵的见解。使用简单的顺序神经网络模型,我们确认医疗处方是 CAC 系统的丰富数据源,与基于文本的模型相比,其计算负载的一小部分提供了有竞争力的检索能力。我们的研究强调了指标选择的重要性,并对模型训练和评估的 ICD 代码子设置相关的现有实践提出了挑战。


























 京公网安备 11010802027423号
京公网安备 11010802027423号