Nature Computational Science ( IF 11.3 ) Pub Date : 2024-02-26 , DOI: 10.1038/s43588-024-00596-6 Téo Lemane , Nolan Lezzoche , Julien Lecubin , Eric Pelletier , Magali Lescot , Rayan Chikhi , Pierre Peterlongo
|
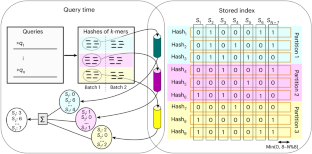
Public sequencing databases contain vast amounts of biological information, yet they are largely underutilized as it is challenging to efficiently search them for any sequence(s) of interest. We present kmindex, an approach that can index thousands of metagenomes and perform sequence searches in a fraction of a second. The index construction is an order of magnitude faster than previous methods, while search times are two orders of magnitude faster. With negligible false positive rates below 0.01%, kmindex outperforms the precision of existing approaches by four orders of magnitude. Here we demonstrate the scalability of kmindex by successfully indexing 1,393 marine seawater metagenome samples from the Tara Oceans project. Additionally, we introduce the publicly accessible web server Ocean Read Atlas, which enables real-time queries on the Tara Oceans dataset.
中文翻译:
使用 kmindex 和 ORA 在 TB 级复杂基因组数据集中建立索引和实时用户友好的查询
公共测序数据库包含大量的生物信息,但它们在很大程度上没有得到充分利用,因为有效地搜索它们以查找任何感兴趣的序列具有挑战性。我们提出了 kmindex,一种可以索引数千个宏基因组并在几分之一秒内执行序列搜索的方法。索引构建比以前的方法快一个数量级,而搜索时间快两个数量级。kmindex 的误报率低于 0.01%,可以忽略不计,其精度比现有方法高出四个数量级。在这里,我们通过成功索引Tara Oceans 项目的 1,393 个海洋海水宏基因组样本来展示 kmindex 的可扩展性。此外,我们还引入了可公开访问的网络服务器 Ocean Read Atlas,它可以对Tara Oceans 数据集进行实时查询。
































 京公网安备 11010802027423号
京公网安备 11010802027423号