当前位置:
X-MOL 学术
›
Inform. Fusion
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Diverse semantic information fusion for Unsupervised Person Re-Identification
Information Fusion ( IF 18.6 ) Pub Date : 2024-02-23 , DOI: 10.1016/j.inffus.2024.102319 Qingsong Hu , Huafeng Li , Zhanxuan Hu , Feiping Nie
Information Fusion ( IF 18.6 ) Pub Date : 2024-02-23 , DOI: 10.1016/j.inffus.2024.102319 Qingsong Hu , Huafeng Li , Zhanxuan Hu , Feiping Nie
|
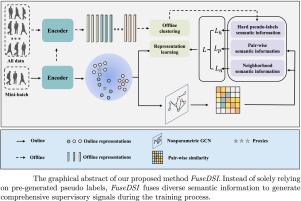
Unsupervised Person Re-Identification (Re-ID) has achieved considerable success through leveraging various approaches that rely on hard pseudo-labels. Prior work mainly focused on improving the quality of pseudo-labels or enhancing the robustness of representation learning model. However, there has been little focus on exploring the contextual semantic information, which can reveal rich relations within samples and provide complementary knowledge to assist the hard pseudo-labels. To this end, we propose a novel method named to explore the potential to harness diverse contextual semantic information fusion. In addition to the hard pseudo labels, explores additional pair-wise semantic information and neighborhood semantic information within each mini-batch through online self-exploration. Furthermore, it leverages the explored semantic information as an additional supervisory signal to enhance robust representation learning. For these two types of contextual semantic information are dynamically estimated in an online manner based on the model’s status, they complement each other well with the hard pseudo-labels. One significant advantage of is its flexibility in combining various pseudo-labels-based methods. Moreover, since exploring the contextual semantic information requires no external elaborate module nor memory-consuming memory bank, it maintains the structure of baseline model with negligible impact on training time. Experimental studies on two widely used person ReID benchmark datasets (MSMT17, Market-1501) demonstrate that consistently improves the performance of baseline model and achieves the state-of-the-art results. Code is available at: .
中文翻译:

用于无监督行人重新识别的多种语义信息融合
无监督人员重新识别(Re-ID)通过利用各种依赖硬伪标签的方法取得了相当大的成功。先前的工作主要集中在提高伪标签的质量或增强表示学习模型的鲁棒性。然而,很少有人关注上下文语义信息的探索,它可以揭示样本内丰富的关系,并提供补充知识来辅助硬伪标签。为此,我们提出了一种新方法,名为探索利用不同上下文语义信息融合的潜力。除了硬伪标签之外,还通过在线自我探索探索每个小批量内的额外成对语义信息和邻域语义信息。此外,它利用探索的语义信息作为额外的监督信号来增强鲁棒的表示学习。由于这两类上下文语义信息是根据模型状态以在线方式动态估计的,因此它们与硬伪标签很好地互补。它的一个显着优点是它可以灵活地组合各种基于伪标签的方法。此外,由于探索上下文语义信息不需要外部复杂的模块或消耗内存的存储体,因此它保持了基线模型的结构,对训练时间的影响可以忽略不计。对两个广泛使用的人员 ReID 基准数据集(MSMT17、Market-1501)的实验研究表明,该数据集持续改进了基线模型的性能并实现了最先进的结果。代码可在以下位置获取: 。
更新日期:2024-02-23
中文翻译:
用于无监督行人重新识别的多种语义信息融合
无监督人员重新识别(Re-ID)通过利用各种依赖硬伪标签的方法取得了相当大的成功。先前的工作主要集中在提高伪标签的质量或增强表示学习模型的鲁棒性。然而,很少有人关注上下文语义信息的探索,它可以揭示样本内丰富的关系,并提供补充知识来辅助硬伪标签。为此,我们提出了一种新方法,名为探索利用不同上下文语义信息融合的潜力。除了硬伪标签之外,还通过在线自我探索探索每个小批量内的额外成对语义信息和邻域语义信息。此外,它利用探索的语义信息作为额外的监督信号来增强鲁棒的表示学习。由于这两类上下文语义信息是根据模型状态以在线方式动态估计的,因此它们与硬伪标签很好地互补。它的一个显着优点是它可以灵活地组合各种基于伪标签的方法。此外,由于探索上下文语义信息不需要外部复杂的模块或消耗内存的存储体,因此它保持了基线模型的结构,对训练时间的影响可以忽略不计。对两个广泛使用的人员 ReID 基准数据集(MSMT17、Market-1501)的实验研究表明,该数据集持续改进了基线模型的性能并实现了最先进的结果。代码可在以下位置获取: 。


























 京公网安备 11010802027423号
京公网安备 11010802027423号