Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2024-01-06 , DOI: 10.1016/j.jbi.2024.104586 Muskan Garg 1 , Xingyi Liu 1 , M S V P J Sathvik 2 , Shaina Raza 3 , Sunghwan Sohn 1
|
Background:
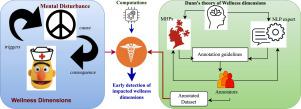
Halbert L. Dunn’s concept of wellness is a multi-dimensional aspect encompassing social and mental well-being. Neglecting these dimensions over time can have a negative impact on an individual’s mental health. The manual efforts employed in in-person therapy sessions reveal that underlying factors of mental disturbance if triggered, may lead to severe mental health disorders.
Objective:
In our research, we introduce a fine-grained approach focused on identifying indicators of wellness dimensions and mark their presence in self-narrated human-writings on Reddit social media platform.
Design and Method:
We present the MultiWD dataset, a curated collection comprising 3281 instances, as a specifically designed and annotated dataset that facilitates the identification of multiple wellness dimensions in Reddit posts. In our study, we introduce the task of identifying wellness dimensions and utilize state-of-the-art classifiers to solve this multi-label classification task.
Results:
Our findings highlights the best and comparative performance of fine-tuned large language models with fine-tuned BERT model. As such, we set BERT as a baseline model to tag wellness dimensions in a user-penned text with F1 score of 76.69.
Conclusion:
Our findings underscore the need of trustworthy and domain-specific knowledge infusion to develop more comprehensive and contextually-aware AI models for tagging and extracting wellness dimensions.
中文翻译:
MultiWD:社交媒体帖子中的多标签健康维度
背景:
哈尔伯特·邓恩 (Halbert L. Dunn) 的健康概念是一个多维度的概念,涵盖社会和心理健康。随着时间的推移,忽视这些维度可能会对个人的心理健康产生负面影响。面对面治疗过程中采用的手动操作表明,如果触发精神障碍的潜在因素,可能会导致严重的精神健康障碍。
客观的:
在我们的研究中,我们引入了一种细粒度的方法,专注于识别健康维度的指标,并在 Reddit 社交媒体平台上的自述人类著作中标记它们的存在。
设计与方法:
我们提供了MultiWD数据集,这是一个包含3281 个实例的精选集合,作为专门设计和注释的数据集,有助于识别 Reddit 帖子中的多个健康维度。在我们的研究中,我们引入了识别健康维度的任务,并利用最先进的分类器来解决这个多标签分类任务。
结果:
我们的研究结果强调了微调大型语言模型与微调 BERT 模型的最佳性能和比较性能。因此,我们将 BERT 设置为基线模型,在 F1 分数为 76.69 的用户编写的文本中标记健康维度。
结论:
我们的研究结果强调需要注入值得信赖和特定领域的知识,以开发更全面和上下文感知的人工智能模型来标记和提取健康维度。










































 京公网安备 11010802027423号
京公网安备 11010802027423号