Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2023-12-07 , DOI: 10.1016/j.jbi.2023.104560 Fuad Abu Zahra , Rohit J. Kate
|
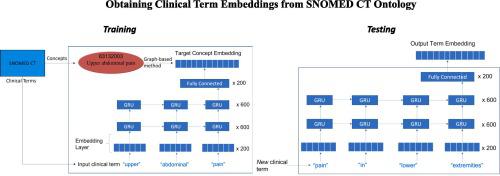
Clinical term embeddings are traditionally obtained using corpus-based methods, however, these methods cannot incorporate knowledge about clinical terms which is already present in medical ontologies. On the other hand, graph-based methods can obtain embeddings of clinical concepts from ontologies, but they cannot obtain embeddings for clinical terms and words. In this paper, a novel method is presented to obtain embeddings for clinical terms and words from the SNOMED CT ontology. The method first obtains embeddings of clinical concepts from SNOMED CT using a graph-based method. Next, these concept embeddings are used as targets to train a deep learning model to map clinical terms to concepts embeddings. The learned model then provides embeddings for clinical terms and words as well as maps novel clinical terms to their embeddings. The embeddings obtained using the method out-performed corpus-based embeddings on the task of predicting clinical term similarity on five benchmark datasets. On the clinical term normalization task, using these embeddings simply as a means of computing similarity between clinical terms obtained accuracy which was competitive to methods trained specifically for this task. Both corpus-based and ontology-based embeddings have a limitation that they tend to learn similar embeddings for opposite or analogous terms. To counter this, we also introduce a method to automatically learn patterns that indicate when two clinical terms represent the same concept and when they represent different concepts. Supplementing the normalization process with these patterns showed improvement. Although clinical term embeddings obtained from SNOMED CT incorporate ontological knowledge which is missed by corpus-based embeddings, they do not incorporate linguistic knowledge which is needed for sentence-based tasks. Hence combining ontology-based embeddings with corpus-based embeddings is an avenue for future work.
中文翻译:
从 SNOMED CT 本体获取临床术语嵌入
传统上,临床术语嵌入是使用基于语料库的方法获得的,然而,这些方法无法合并医学本体中已经存在的临床术语知识。另一方面,基于图的方法可以从本体中获得临床概念的嵌入,但无法获得临床术语和单词的嵌入。本文提出了一种从 SNOMED CT 本体中获取临床术语和单词嵌入的新方法。该方法首先使用基于图的方法从 SNOMED CT 获取临床概念的嵌入。接下来,这些概念嵌入用作训练深度学习模型的目标,以将临床术语映射到概念嵌入。然后,学习的模型提供临床术语和单词的嵌入,并将新的临床术语映射到它们的嵌入。在五个基准数据集上预测临床术语相似性的任务中,使用该方法获得的嵌入优于基于语料库的嵌入。在临床术语标准化任务中,简单地使用这些嵌入作为计算临床术语之间相似性的方法,所获得的准确性与专门为此任务训练的方法具有竞争力。基于语料库和基于本体的嵌入都有一个局限性,即它们倾向于学习相反或类似术语的相似嵌入。为了解决这个问题,我们还引入了一种自动学习模式的方法,这些模式指示两个临床术语何时代表相同的概念以及何时代表不同的概念。用这些模式补充标准化过程显示出改进。 尽管从 SNOMED CT 获得的临床术语嵌入包含了基于语料库的嵌入所遗漏的本体论知识,但它们并未包含基于句子的任务所需的语言知识。因此,将基于本体的嵌入与基于语料库的嵌入相结合是未来工作的一个途径。


























 京公网安备 11010802027423号
京公网安备 11010802027423号