Journal of Biomedical informatics ( IF 4.5 ) Pub Date : 2023-12-01 , DOI: 10.1016/j.jbi.2023.104548 Ramon Correa , Khushbu Pahwa , Bhavik Patel , Celine M. Vachon , Judy W. Gichoya , Imon Banerjee
|
Background:
A major hurdle for the real time deployment of the AI models is ensuring trustworthiness of these models for the unseen population. More often than not, these complex models are black boxes in which promising results are generated. However, when scrutinized, these models begin to reveal implicit biases during the decision making, particularly for the minority subgroups.
Method:
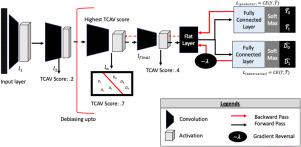
We develop an efficient adversarial de-biasing approach with partial learning by incorporating the existing concept activation vectors (CAV) methodology, to reduce racial disparities while preserving the performance of the targeted task. CAV is originally a model interpretability technique which we adopted to identify convolution layers responsible for learning race and only fine-tune up to that layer instead of fine-tuning the complete network, limiting the drop in performance
Results:
The methodology has been evaluated on two independent medical image case-studies - chest X-ray and mammograms, and we also performed external validation on a different racial population. On the external datasets for the chest X-ray use-case, debiased models (averaged AUC 0.87 ) outperformed the baseline convolution models (averaged AUC 0.57 ) as well as the models trained with the popular fine-tuning strategy (averaged AUC 0.81). Moreover, the mammogram models is debiased using a single dataset (white, black and Asian) and improved the performance on an external datasets (averaged AUC 0.8 to 0.86 ) with completely different population (primarily Hispanic patients).
Conclusion:
In this study, we demonstrated that the adversarial models trained only with internal data performed equally or often outperformed the standard fine-tuning strategy with data from an external setting. The adversarial training approach described can be applied regardless of predictor’s model architecture, as long as the convolution model is trained using a gradient-based method. We release the training code with academic open-source license - https://github.com/ramon349/JBI2023_TCAV_debiasing.
中文翻译:
使用概念激活向量进行有效的对抗性去偏——医学图像案例研究
背景:
实时部署人工智能模型的一个主要障碍是确保这些模型对于看不见的人群的可信度。通常,这些复杂的模型是黑匣子,在其中产生有希望的结果。然而,经过仔细审查,这些模型开始揭示决策过程中隐含的偏见,特别是对于少数群体。
方法:
我们通过结合现有的概念激活向量(CAV)方法,开发了一种具有部分学习的有效对抗性去偏见方法,以减少种族差异,同时保持目标任务的性能。CAV 最初是一种模型可解释性技术,我们采用它来识别负责学习竞赛的卷积层,并且仅对该层进行微调,而不是对整个网络进行微调,从而限制了性能下降
结果:
该方法已在两个独立的医学图像案例研究(胸部 X 光检查和乳房 X 光检查)中进行了评估,并且我们还对不同种族人群进行了外部验证。在胸部 X 射线用例的外部数据集上,去偏模型(平均 AUC 0.87)优于基线卷积模型(平均 AUC 0.57)以及使用流行的微调策略训练的模型(平均 AUC 0.81)。此外,乳房 X 光检查模型使用单个数据集(白人、黑人和亚洲人)进行去偏,并提高了完全不同人群(主要是西班牙裔患者)的外部数据集(平均 AUC 0.8 至 0.86)的性能。
结论:
在这项研究中,我们证明了仅使用内部数据训练的对抗模型表现相同或经常优于使用外部设置数据的标准微调策略。只要使用基于梯度的方法训练卷积模型,无论预测器的模型架构如何,都可以应用所描述的对抗性训练方法。我们以学术开源许可证发布训练代码 - https://github.com/ramon349/JBI2023_TCAV_debiasing。


























 京公网安备 11010802027423号
京公网安备 11010802027423号