Speech Communication ( IF 3.2 ) Pub Date : 2023-07-22 , DOI: 10.1016/j.specom.2023.102959 Andrea Vidal , Carlos Busso
|
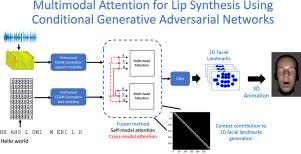
The synthesis of lip movements is an important problem for a socially interactive agent (SIA). It is important to generate lip movements that are synchronized with speech and have realistic co-articulation. We hypothesize that combining lexical information (i.e., sequence of phonemes) and acoustic features can lead not only to models that generate the correct lip movements matching the articulatory movements, but also to trajectories that are well synchronized with the speech emphasis and emotional content. This work presents attention-based frameworks that use acoustic and lexical information to enhance the synthesis of lip movements. The lexical information is obtained from automatic speech recognition (ASR) transcriptions, broadening the range of applications of the proposed solution. We propose models based on conditional generative adversarial networks (CGAN) with self-modality attention and cross-modalities attention mechanisms. These models allow us to understand which frames are considered more in the generation of lip movements. We animate the synthesized lip movements using blendshapes. These animations are used to compare our proposed multimodal models with alternative methods, including unimodal models implemented with either text or acoustic features. We rely on subjective metrics using perceptual evaluations and an objective metric based on the LipSync model. The results show that our proposed models with attention mechanisms are preferred over the baselines on the perception of naturalness. The addition of cross-modality attentions and self-modality attentions has a significant positive impact on the performance of the generated sequences. We observe that lexical information provides valuable information even when the transcriptions are not perfect. The improved performance observed by the multimodal system confirms the complementary information provided by the speech and text modalities.
中文翻译:
使用条件生成对抗网络进行唇部合成的多模态注意力
嘴唇运动的合成对于社交互动主体(SIA)来说是一个重要问题。生成与语音同步并具有真实的协同发音的嘴唇运动非常重要。我们假设,结合词汇信息(即音素序列)和声学特征不仅可以产生与发音运动相匹配的正确嘴唇运动的模型,而且可以产生与语音重点和情感内容很好同步的轨迹。这项工作提出了基于注意力的框架,该框架使用声音和词汇信息来增强嘴唇运动的合成。词汇信息通过自动语音识别获得(ASR)转录,扩大了所提出解决方案的应用范围。我们提出基于条件生成对抗网络的模型(CGAN)具有自模态注意和跨模态注意机制。这些模型使我们能够了解哪些帧在嘴唇运动的生成中被更多地考虑。我们使用混合形状对合成的嘴唇运动进行动画处理。这些动画用于将我们提出的多模态模型与替代方法进行比较,包括使用文本或声学特征实现的单模态模型。我们依靠使用感知评估的主观指标和基于 LipSync 模型的客观指标。结果表明,我们提出的具有注意机制的模型在自然感知方面优于基线。跨模态注意力和自模态注意力的添加对生成序列的性能具有显着的积极影响。我们观察到,即使转录不完美,词汇信息也能提供有价值的信息。多模态系统观察到的性能改进证实了语音和文本模态提供的补充信息。


























 京公网安备 11010802027423号
京公网安备 11010802027423号