Nature Biotechnology ( IF 33.1 ) Pub Date : 2023-05-25 , DOI: 10.1038/s41587-023-01767-y Yuhan Hao 1, 2 , Tim Stuart 1, 2 , Madeline H Kowalski 2, 3 , Saket Choudhary 1, 2 , Paul Hoffman 1 , Austin Hartman 1 , Avi Srivastava 1, 2 , Gesmira Molla 2 , Shaista Madad 1, 2 , Carlos Fernandez-Granda 4, 5 , Rahul Satija 1, 2
|
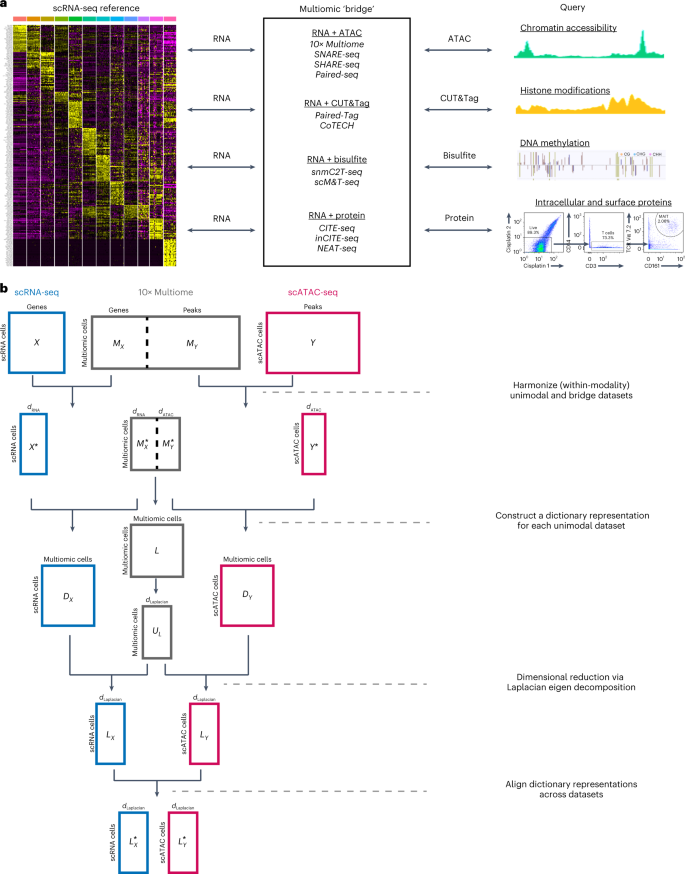
Mapping single-cell sequencing profiles to comprehensive reference datasets provides a powerful alternative to unsupervised analysis. However, most reference datasets are constructed from single-cell RNA-sequencing data and cannot be used to annotate datasets that do not measure gene expression. Here we introduce ‘bridge integration’, a method to integrate single-cell datasets across modalities using a multiomic dataset as a molecular bridge. Each cell in the multiomic dataset constitutes an element in a ‘dictionary’, which is used to reconstruct unimodal datasets and transform them into a shared space. Our procedure accurately integrates transcriptomic data with independent single-cell measurements of chromatin accessibility, histone modifications, DNA methylation and protein levels. Moreover, we demonstrate how dictionary learning can be combined with sketching techniques to improve computational scalability and harmonize 8.6 million human immune cell profiles from sequencing and mass cytometry experiments. Our approach, implemented in version 5 of our Seurat toolkit (http://www.satijalab.org/seurat), broadens the utility of single-cell reference datasets and facilitates comparisons across diverse molecular modalities.
中文翻译:
用于集成、多模式和可扩展单细胞分析的字典学习
将单细胞测序图谱映射到综合参考数据集为无监督分析提供了强大的替代方案。然而,大多数参考数据集是根据单细胞 RNA 测序数据构建的,不能用于注释不测量基因表达的数据集。在这里,我们介绍“桥集成”,这是一种使用多组学数据集作为分子桥来跨模式集成单细胞数据集的方法。多组学数据集中的每个单元构成“字典”中的一个元素,用于重建单峰数据集并将其转换为共享空间。我们的程序准确地将转录组数据与染色质可及性、组蛋白修饰、DNA 甲基化和蛋白质水平的独立单细胞测量相结合。此外,我们还演示了如何将字典学习与草图技术相结合,以提高计算可扩展性并协调来自测序和质谱流式实验的 860 万个人类免疫细胞图谱。我们的方法在 Seurat 工具包第 5 版 (http://www.satijalab.org/seurat) 中实施,扩大了单细胞参考数据集的实用性,并促进了不同分子模式之间的比较。










































 京公网安备 11010802027423号
京公网安备 11010802027423号