Journal of Molecular Evolution ( IF 1.8 ) Pub Date : 2023-01-18 , DOI: 10.1007/s00239-022-10083-z Milo S. Johnson , Sandeep Venkataram , Sergey Kryazhimskiy
|
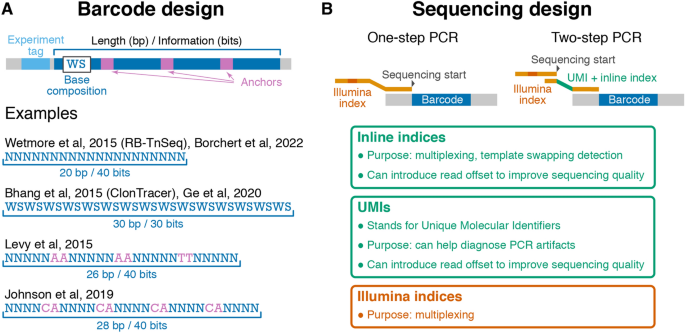
Random DNA barcodes are a versatile tool for tracking cell lineages, with applications ranging from development to cancer to evolution. Here, we review and critically evaluate barcode designs as well as methods of barcode sequencing and initial processing of barcode data. We first demonstrate how various barcode design decisions affect data quality and propose a new design that balances all considerations that we are currently aware of. We then discuss various options for the preparation of barcode sequencing libraries, including inline indices and Unique Molecular Identifiers (UMIs). Finally, we test the performance of several established and new bioinformatic pipelines for the extraction of barcodes from raw sequencing reads and for error correction. We find that both alignment and regular expression-based approaches work well for barcode extraction, and that error-correction pipelines designed specifically for barcode data are superior to generic ones. Overall, this review will help researchers to approach their barcoding experiments in a deliberate and systematic way.
中文翻译:
设计、测序和鉴定随机 DNA 条形码的最佳实践
随机 DNA 条形码是一种用于追踪细胞谱系的多功能工具,应用范围从发育到癌症再到进化。在这里,我们回顾并批判性地评估了条形码设计以及条形码排序和条形码数据初始处理的方法。我们首先演示了各种条形码设计决策如何影响数据质量,并提出了一种平衡我们目前知道的所有考虑因素的新设计。然后,我们讨论了制备条形码测序文库的各种选项,包括在线索引和唯一分子标识符 (UMI)。最后,我们测试了几种已建立和新的生物信息学管道的性能,用于从原始测序读数中提取条形码和纠错。我们发现,对齐和基于正则表达式的方法都适用于条形码提取,并且专为条形码数据设计的纠错管道优于通用管道。总的来说,这篇综述将帮助研究人员以深思熟虑和系统的方式进行他们的条形码实验。






















































 京公网安备 11010802027423号
京公网安备 11010802027423号