Complex & Intelligent Systems ( IF 5.0 ) Pub Date : 2022-11-25 , DOI: 10.1007/s40747-022-00914-3 Jun Tang , Baodi Liu , Wenhui Guo , Yanjiang Wang
|
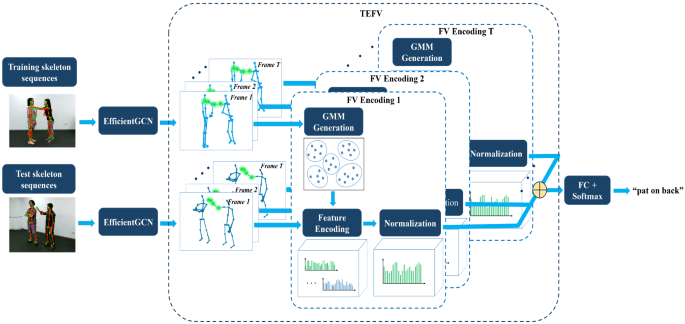
The key to skeleton-based action recognition is how to extract discriminative features from skeleton data. Recently, graph convolutional networks (GCNs) are proven to be highly successful for skeleton-based action recognition. However, existing GCN-based methods focus on extracting robust features while neglecting the information of feature distributions. In this work, we aim to introduce Fisher vector (FV) encoding into GCN to effectively utilize the information of feature distributions. However, since the Gaussian Mixture Model (GMM) is employed to fit the global distribution of features, Fisher vector encoding inevitably leads to losing temporal information of actions, which is demonstrated by our analysis. To tackle this problem, we propose a temporal enhanced Fisher vector encoding algorithm (TEFV) to provide more discriminative visual representation. Compared with FV, our TEFV model can not only preserve the temporal information of the entire action but also capture fine-grained spatial configurations and temporal dynamics. Moreover, we propose a two-stream framework (2sTEFV-GCN) by combining the TEFV model with the GCN model to further improve the performance. On two large-scale datasets for skeleton-based action recognition, NTU-RGB+D 60 and NTU-RGB+D 120, our model achieves state-of-the-art performance.
中文翻译:
用于基于骨架的动作识别的双流时间增强 Fisher 矢量编码
基于骨架的动作识别的关键是如何从骨架数据中提取判别特征。最近,图卷积网络 (GCN) 被证明在基于骨架的动作识别方面非常成功。然而,现有的基于 GCN 的方法侧重于提取鲁棒特征,而忽略了特征分布的信息。在这项工作中,我们旨在将 Fisher 向量 (FV) 编码引入 GCN 以有效利用特征分布的信息。然而,由于采用高斯混合模型 (GMM) 来拟合特征的全局分布,Fisher 向量编码不可避免地导致丢失动作的时间信息,我们的分析证明了这一点。为了解决这个问题,我们提出了一种时间增强的 Fisher 矢量编码算法 (TEFV),以提供更具辨别力的视觉表示。与 FV 相比,我们的 TEFV 模型不仅可以保留整个动作的时间信息,还可以捕获细粒度的空间配置和时间动态。此外,我们通过将 TEFV 模型与 GCN 模型相结合,提出了一种双流框架(2sTEFV-GCN),以进一步提高性能。在用于基于骨架的动作识别的两个大型数据集 NTU-RGB+D 60 和 NTU-RGB+D 120 上,我们的模型实现了最先进的性能。我们通过将 TEFV 模型与 GCN 模型相结合,提出了一个双流框架(2sTEFV-GCN),以进一步提高性能。在用于基于骨架的动作识别的两个大型数据集 NTU-RGB+D 60 和 NTU-RGB+D 120 上,我们的模型实现了最先进的性能。我们通过将 TEFV 模型与 GCN 模型相结合,提出了一个双流框架(2sTEFV-GCN),以进一步提高性能。在用于基于骨架的动作识别的两个大型数据集 NTU-RGB+D 60 和 NTU-RGB+D 120 上,我们的模型实现了最先进的性能。










































 京公网安备 11010802027423号
京公网安备 11010802027423号