Neural Processing Letters ( IF 2.6 ) Pub Date : 2022-09-24 , DOI: 10.1007/s11063-022-11042-x Mingwen Bi , Jiaqi Li , Xinliang Liu , Qingchuan Zhang , Zhenghong Yang
|
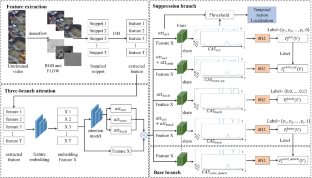
Weakly-supervised temporal action localization aims to detect the temporal boundaries of action instances in untrimmed videos only by relying on video-level action labels. The main challenge of the research is to accurately segment the action from the background in the absence of frame-level labels. Previous methods consider the action-related context in the background as the main factor restricting the segmentation performance. Most of them take action labels as pseudo-labels for context and suppress context frames in class activation sequences using the attention mechanism. However, this only applies to fixed shots or videos with a single theme. For videos with frequent scene switching and complicated themes, such as casual shots of unexpected events and secret shots, the strong randomness and weak continuity of the action cause the assumption not to be valid. In addition, the wrong pseudo-labels will enhance the weight of context frames, which will affect the segmentation performance. To address above issues, in this paper, we define a new video frame division standard (action instance, action-related context, no-action background), propose an Action-aware Network with Upper and Lower loss AUL-Net, which limits the activation of context to a reasonable range through a two-branch weight-sharing framework with a three-branch attention mechanism, so that the model has wider applicability while accurately suppressing context and background. We conducted extensive experiments on the self-built food safety video dataset FS-VA, and the results show that our method outperforms the state-of-the-art model.
中文翻译:
用于弱监督时间动作定位的具有上下限损失的动作感知网络
弱监督时间动作定位旨在仅依靠视频级动作标签来检测未修剪视频中动作实例的时间边界。该研究的主要挑战是在没有帧级标签的情况下准确地从背景中分割动作。以前的方法将背景中与动作相关的上下文视为限制分割性能的主要因素。他们中的大多数将动作标签作为上下文的伪标签,并使用注意机制抑制类激活序列中的上下文帧。但是,这仅适用于具有单一主题的固定镜头或视频。对于场景切换频繁、主题复杂的视频,如突发事件的随手拍、秘密拍摄等,动作的强随机性和弱连续性导致假设不成立。此外,错误的伪标签会增强上下文帧的权重,从而影响分割性能。针对上述问题,在本文中,我们定义了一个新的视频帧划分标准(动作实例、动作相关上下文、无动作背景),提出了一种具有上下损失的AUL-Net的Action-aware Network。通过具有三分支注意力机制的两分支权重共享框架将上下文激活到合理范围,使模型在准确抑制上下文和背景的同时具有更广泛的适用性。我们对自建的食品安全视频数据集 FS-VA 进行了广泛的实验,结果表明我们的方法优于最先进的模型。这将影响分割性能。针对上述问题,在本文中,我们定义了一个新的视频帧划分标准(动作实例、动作相关上下文、无动作背景),提出了一种具有上下损失的AUL-Net的Action-aware Network。通过具有三分支注意力机制的两分支权重共享框架将上下文激活到合理范围,使模型在准确抑制上下文和背景的同时具有更广泛的适用性。我们对自建的食品安全视频数据集 FS-VA 进行了广泛的实验,结果表明我们的方法优于最先进的模型。这将影响分割性能。针对上述问题,在本文中,我们定义了一个新的视频帧划分标准(动作实例、动作相关上下文、无动作背景),提出了一种具有上下损失的AUL-Net的Action-aware Network。通过具有三分支注意力机制的两分支权重共享框架将上下文激活到合理范围,使模型在准确抑制上下文和背景的同时具有更广泛的适用性。我们对自建的食品安全视频数据集 FS-VA 进行了广泛的实验,结果表明我们的方法优于最先进的模型。no-action background),提出了一种Action-aware Network with Upper and Lower loss AUL-Net,通过具有三分支注意力机制的二分支权重共享框架将上下文的激活限制在合理范围内,使得该模型具有更广泛的适用性,同时准确地抑制了上下文和背景。我们对自建的食品安全视频数据集 FS-VA 进行了广泛的实验,结果表明我们的方法优于最先进的模型。no-action background),提出了一种Action-aware Network with Upper and Lower loss AUL-Net,通过具有三分支注意力机制的二分支权重共享框架将上下文的激活限制在合理范围内,使得该模型具有更广泛的适用性,同时准确地抑制了上下文和背景。我们对自建的食品安全视频数据集 FS-VA 进行了广泛的实验,结果表明我们的方法优于最先进的模型。









































 京公网安备 11010802027423号
京公网安备 11010802027423号