Nature Communications ( IF 15.7 ) Pub Date : 2022-08-30 , DOI: 10.1038/s41467-022-32012-w Kevin Ellis , Adam Albright , Armando Solar-Lezama , Joshua B. Tenenbaum , Timothy J. O’Donnell
|
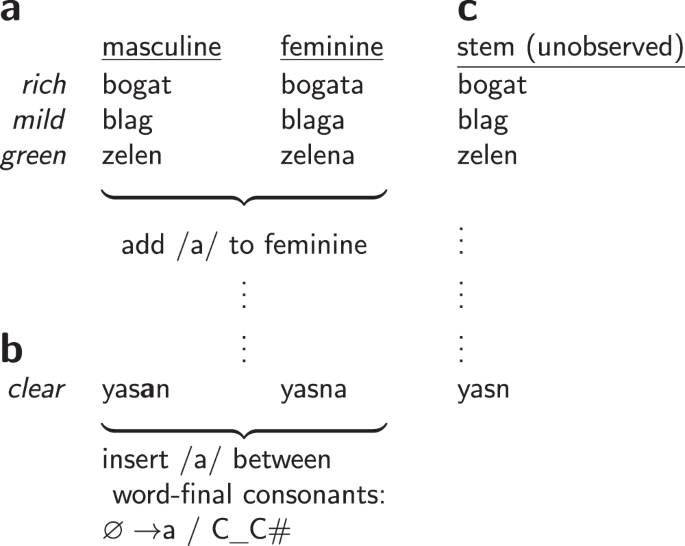
Automated, data-driven construction and evaluation of scientific models and theories is a long-standing challenge in artificial intelligence. We present a framework for algorithmically synthesizing models of a basic part of human language: morpho-phonology, the system that builds word forms from sounds. We integrate Bayesian inference with program synthesis and representations inspired by linguistic theory and cognitive models of learning and discovery. Across 70 datasets from 58 diverse languages, our system synthesizes human-interpretable models for core aspects of each language’s morpho-phonology, sometimes approaching models posited by human linguists. Joint inference across all 70 data sets automatically synthesizes a meta-model encoding interpretable cross-language typological tendencies. Finally, the same algorithm captures few-shot learning dynamics, acquiring new morphophonological rules from just one or a few examples. These results suggest routes to more powerful machine-enabled discovery of interpretable models in linguistics and other scientific domains.
中文翻译:
用贝叶斯程序归纳综合人类语言理论
自动化的、数据驱动的科学模型和理论的构建和评估是人工智能中长期存在的挑战。我们提出了一个算法合成人类语言基本部分模型的框架:形态音韵学,从声音构建单词形式的系统。我们将贝叶斯推理与受语言理论和学习和发现的认知模型启发的程序合成和表示相结合。在来自 58 种不同语言的 70 个数据集中,我们的系统综合了每种语言形态音系核心方面的人类可解释模型,有时接近人类语言学家提出的模型。所有 70 个数据集的联合推理自动合成一个元模型编码可解释的跨语言类型趋势。最后,相同的算法捕获了小样本的学习动态,仅从一个或几个示例中获取新的形态语音规则。这些结果表明了在语言学和其他科学领域中更强大的机器支持发现可解释模型的途径。






















































 京公网安备 11010802027423号
京公网安备 11010802027423号