Neural Processing Letters ( IF 2.6 ) Pub Date : 2022-08-18 , DOI: 10.1007/s11063-022-10990-8 Zaid Alyafeai , Maged S. Al-shaibani , Mustafa Ghaleb , Irfan Ahmad
|
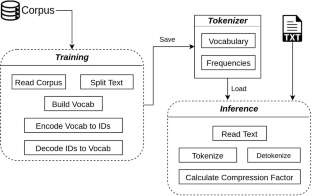
The first step in any NLP pipeline is to split the text into individual tokens. The most obvious and straightforward approach is to use words as tokens. However, given a large text corpus, representing all the words is not efficient in terms of vocabulary size. In the literature, many tokenization algorithms have emerged to tackle this problem by creating subwords, which in turn limits the vocabulary size in a given text corpus. Most tokenization techniques are language-agnostic, i.e., they do not incorporate the linguistic features of a given language. Not to mention the difficulty of evaluating such techniques in practice. In this paper, we introduce three new tokenization algorithms for Arabic and compare them to other three popular tokenizers using unsupervised evaluations. In addition, we compare all the six tokenizers by evaluating them on three supervised classification tasks: sentiment analysis, news classification and poem-meter classification, using six publicly available datasets. Our experiments show that none of the tokenization techniques is the best choice overall and that the performance of a given tokenization algorithm depends on many factors including the size of the dataset, nature of the task, and the morphology richness of the dataset. However, some tokenization techniques are better overall as compared to others on various text classification tasks.
中文翻译:
评估用于阿拉伯文本分类的各种标记器
任何 NLP 管道的第一步都是将文本拆分为单独的标记。最明显和最直接的方法是使用单词作为标记。然而,给定一个大的文本语料库,就词汇量而言,表示所有的单词效率不高。在文献中,出现了许多标记化算法来通过创建子词来解决这个问题,这反过来又限制了给定文本语料库中的词汇量。大多数标记化技术与语言无关,即它们不包含给定语言的语言特征。更不用说在实践中评估这些技术的难度了。在本文中,我们介绍了三种新的阿拉伯语分词算法,并将它们与其他三种使用无监督评估的流行分词器进行比较。此外,我们使用六个公开可用的数据集,通过在三个监督分类任务上评估所有六个标记器来比较所有六个标记器:情感分析、新闻分类和诗歌计量分类。我们的实验表明,总体而言,没有一种标记化技术是最佳选择,并且给定标记化算法的性能取决于许多因素,包括数据集的大小、任务的性质和数据集的形态丰富度。然而,在各种文本分类任务上,一些标记化技术总体上比其他技术更好。我们的实验表明,总体而言,没有一种标记化技术是最佳选择,并且给定标记化算法的性能取决于许多因素,包括数据集的大小、任务的性质和数据集的形态丰富度。然而,在各种文本分类任务上,一些标记化技术总体上比其他技术更好。我们的实验表明,总体而言,没有一种标记化技术是最佳选择,并且给定标记化算法的性能取决于许多因素,包括数据集的大小、任务的性质和数据集的形态丰富度。然而,在各种文本分类任务上,一些标记化技术总体上比其他技术更好。










































 京公网安备 11010802027423号
京公网安备 11010802027423号