Journal of Signal Processing Systems ( IF 1.6 ) Pub Date : 2022-07-26 , DOI: 10.1007/s11265-022-01797-w Nermine Ali , Jean-Marc Philippe , Benoit Tain , Philippe Coussy
|
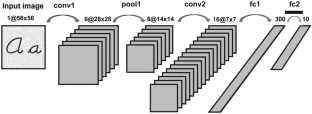
The wide landscape of memory-hungry and compute-intensive Convolutional Neural Networks (CNNs) is quickly changing. CNNs are continuously evolving by introducing new layers or optimization strategies to either improve accuracy, reduce memory and computational needs or both. Moving such algorithms to on-device enables smarter edge products. However, hardware designers find this constant evolution hard to master, which keeps CNN accelerators one step behind. More approaches are using reconfigurable hardware, such as FPGAs, to design customized inference accelerators that are more suited to the newly-emerging CNN algorithms. Moreover, high-level design techniques, such as High-Level Synthesis (HLS), are adopted to address the time-consuming RTL-based design and the design space exploration problems. HLS allows generating RTL source code from high-level descriptions. This paper presents a hardware accelerator generation framework targeting FPGAs that relies on two steps. The first step characterizes the input CNN and produces hardware-aware metrics. The second step exploits the generated metrics to produce an optimized C-HLS source code for each layer of the input CNN, then it uses an HLS tool to generate a synthesizable RTL representation of the inference accelerator. The main goal of this approach is to reduce the gap between the evolving CNNs and the hardware accelerators, thus reducing design time of new systems.
中文翻译:
从高级描述生成高效的基于 FPGA 的 CNN 加速器
需要大量内存和计算密集型卷积神经网络 (CNN) 的广阔前景正在迅速发生变化。CNN 通过引入新层或优化策略来不断发展,以提高准确性、减少内存和计算需求或两者兼而有之。将此类算法转移到设备上可以实现更智能的边缘产品。然而,硬件设计人员发现这种不断的演变很难掌握,这使得 CNN 加速器落后了一步。更多方法正在使用可重构硬件(例如 FPGA)来设计更适合新出现的 CNN 算法的定制推理加速器。此外,采用高级设计技术,如高级综合(HLS)来解决耗时的基于 RTL 的设计和设计空间探索问题。HLS 允许从高级描述生成 RTL 源代码。本文提出了一个针对 FPGA 的硬件加速器生成框架,它依赖于两个步骤。第一步表征输入 CNN 并产生硬件感知指标。第二步利用生成的指标为输入 CNN 的每一层生成优化的 C-HLS 源代码,然后使用 HLS 工具生成推理加速器的可合成 RTL 表示。这种方法的主要目标是减少不断发展的 CNN 和硬件加速器之间的差距,从而减少新系统的设计时间。第二步利用生成的指标为输入 CNN 的每一层生成优化的 C-HLS 源代码,然后使用 HLS 工具生成推理加速器的可合成 RTL 表示。这种方法的主要目标是减少不断发展的 CNN 和硬件加速器之间的差距,从而减少新系统的设计时间。第二步利用生成的指标为输入 CNN 的每一层生成优化的 C-HLS 源代码,然后使用 HLS 工具生成推理加速器的可合成 RTL 表示。这种方法的主要目标是减少不断发展的 CNN 和硬件加速器之间的差距,从而减少新系统的设计时间。










































 京公网安备 11010802027423号
京公网安备 11010802027423号