Complex & Intelligent Systems ( IF 5.0 ) Pub Date : 2022-07-20 , DOI: 10.1007/s40747-022-00807-5 Vinay Kukreja
|
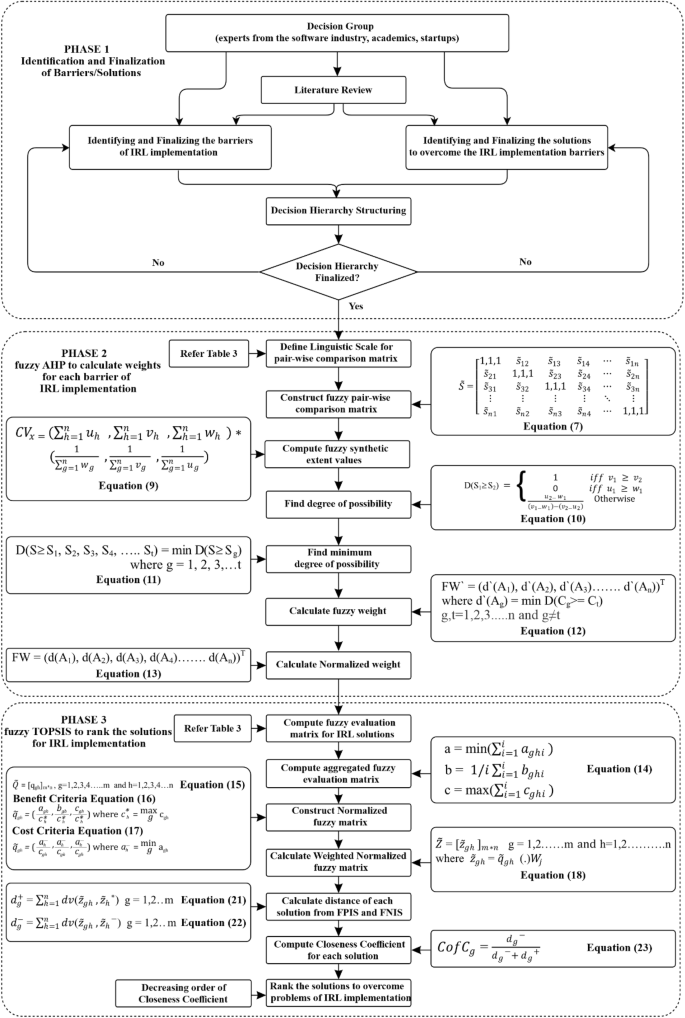
Reinforcement learning (RL) techniques nurture building up solutions for sequential decision-making problems under uncertainty and ambiguity. RL has agents with a reward function that interacts with a dynamic environment to find out an optimal policy. There are problems associated with RL like the reward function should be specified in advance, design difficulties and unable to handle large complex problems, etc. This led to the development of inverse reinforcement learning (IRL). IRL also suffers from many problems in real life like robust reward functions, ill-posed problems, etc., and different solutions have been proposed to solve these problems like maximum entropy, support for multiple rewards and non-linear reward functions, etc. There are majorly eight problems associated with IRL and eight solutions have been proposed to solve IRL problems. This paper has proposed a hybrid fuzzy AHP–TOPSIS approach to prioritize the solutions while implementing IRL. Fuzzy Analytical Hierarchical Process (FAHP) is used to get the weights of identified problems. The relative accuracy and root-mean-squared error using FAHP are 97.74 and 0.0349, respectively. Fuzzy Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) uses these FAHP weights to prioritize the solutions. The most significant problem in IRL implementation is of ‘lack of robust reward functions’ weighting 0.180, whereas the most significant solution in IRL implementation is ‘Supports optimal policy and rewards functions along with stochastic transition models’ having closeness of coefficient (CofC) value of 0.967156846.
中文翻译:
混合模糊 AHP-TOPSIS 方法对逆强化学习的解决方案进行优先排序
强化学习 (RL) 技术培养了在不确定性和模糊性下为顺序决策问题建立解决方案。RL 具有具有奖励功能的代理,该功能与动态环境交互以找出最佳策略。与强化学习相关的问题,如需要提前指定奖励函数、设计困难以及无法处理大型复杂问题等。这导致了逆强化学习(IRL)的发展。IRL 在现实生活中也存在许多问题,如鲁棒奖励函数、不适定问题等,并且已经提出了不同的解决方案来解决这些问题,如最大熵、支持多个奖励和非线性奖励函数等。主要有八个与 IRL 相关的问题,并且已经提出了八种解决方案来解决 IRL 问题。本文提出了一种混合模糊 AHP-TOPSIS 方法来在实施 IRL 时对解决方案进行优先级排序。模糊层次分析法 (FAHP) 用于获取已识别问题的权重。使用 FAHP 的相对精度和均方根误差分别为 97.74 和 0.0349。与理想解决方案相似度排序的模糊技术 (TOPSIS) 使用这些 FAHP 权重来确定解决方案的优先级。IRL 实施中最重要的问题是“缺乏强大的奖励函数”权重为 0.180,










































 京公网安备 11010802027423号
京公网安备 11010802027423号