Medical Image Analysis ( IF 10.9 ) Pub Date : 2022-07-13 , DOI: 10.1016/j.media.2022.102535 Yan Wang 1 , Yangqin Feng 1 , Lei Zhang 2 , Joey Tianyi Zhou 1 , Yong Liu 1 , Rick Siow Mong Goh 1 , Liangli Zhen 1
|
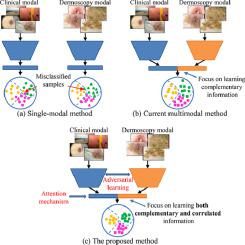
Accurate skin lesion diagnosis requires a great effort from experts to identify the characteristics from clinical and dermoscopic images. Deep multimodal learning-based methods can reduce intra- and inter-reader variability and improve diagnostic accuracy compared to the single modality-based methods. This study develops a novel method, named adversarial multimodal fusion with attention mechanism (AMFAM), to perform multimodal skin lesion classification. Specifically, we adopt a discriminator that uses adversarial learning to enforce the feature extractor to learn the correlated information explicitly. Moreover, we design an attention-based reconstruction strategy to encourage the feature extractor to concentrate on learning the features of the lesion area, thus, enhancing the feature vector from each modality with more discriminative information. Unlike existing multimodal-based approaches, which only focus on learning complementary features from dermoscopic and clinical images, our method considers both correlated and complementary information of the two modalities for multimodal fusion. To verify the effectiveness of our method, we conduct comprehensive experiments on a publicly available multimodal and multi-task skin lesion classification dataset: 7-point criteria evaluation database. The experimental results demonstrate that our proposed method outperforms the current state-of-the-art methods and improves the average AUC score by above on the test set.
中文翻译:
使用临床和皮肤镜图像进行皮肤病变分类的对抗性多模态融合与注意机制
准确的皮肤病变诊断需要专家付出巨大努力,从临床和皮肤镜图像中识别特征。与基于单一模态的方法相比,基于深度多模态学习的方法可以减少读者内部和读者间的可变性并提高诊断准确性。本研究开发了一种名为对抗性多模态融合与注意机制 (AMFAM) 的新方法来执行多模态皮肤损伤分类。具体来说,我们采用了一种使用对抗性学习的鉴别器来强制特征提取器明确地学习相关信息。此外,我们设计了一种基于注意力的重建策略,以鼓励特征提取器专注于学习病变区域的特征,从而用更具辨别力的信息增强来自每种模态的特征向量。与现有的基于多模态的方法仅侧重于从皮肤镜和临床图像中学习互补特征不同,我们的方法考虑了多模态融合的两种模态的相关信息和互补信息。为了验证我们方法的有效性,我们对公开可用的多模式和多任务皮肤病变分类数据集:7 点标准评估数据库进行了综合实验。实验结果表明,我们提出的方法优于当前最先进的方法,并将平均 AUC 分数提高了以上 为了验证我们方法的有效性,我们对公开可用的多模式和多任务皮肤病变分类数据集:7 点标准评估数据库进行了综合实验。实验结果表明,我们提出的方法优于当前最先进的方法,并将平均 AUC 分数提高了以上 为了验证我们方法的有效性,我们对公开可用的多模式和多任务皮肤病变分类数据集:7 点标准评估数据库进行了综合实验。实验结果表明,我们提出的方法优于当前最先进的方法,并将平均 AUC 分数提高了以上在测试集上。


























 京公网安备 11010802027423号
京公网安备 11010802027423号