Machine Vision and Applications ( IF 2.4 ) Pub Date : 2022-07-08 , DOI: 10.1007/s00138-022-01323-9 João Paulo Lima , Rafael Roberto , Lucas Figueiredo , Francisco Simões , Diego Thomas , Hideaki Uchiyama , Veronica Teichrieb
|
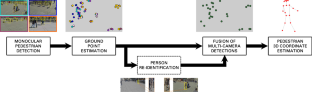
Pedestrian detection is a critical problem in many areas, such as smart cities, surveillance, monitoring, autonomous driving, and robotics. AI-based methods have made tremendous progress in the field in the last few years, but good performance is limited to data that match the training datasets. We present a multi-camera 3D pedestrian detection method that does not need to be trained using data from the target scene. The core idea of our approach consists in formulating consistency in multiple views as a graph clique cover problem. We estimate pedestrian ground location on the image plane using a novel method based on human body poses and person’s bounding boxes from an off-the-shelf monocular detector. We then project these locations onto the ground plane and fuse them with a new formulation of a clique cover problem from graph theory. We propose a new vertex ordering strategy to define fusion priority based on both detection distance and vertex degree. We also propose an optional step for exploiting pedestrian appearance during fusion by using a domain-generalizable person re-identification model. Finally, we compute the final 3D ground coordinates of each detected pedestrian with a method based on keypoint triangulation. We evaluated the proposed approach on the challenging WILDTRACK and MultiviewX datasets. Our proposed method significantly outperformed state of the art in terms of generalizability. It obtained a MODA that was approximately 15% and 2% better than the best existing generalizable detection technique on WILDTRACK and MultiviewX, respectively.
中文翻译:
使用多个摄像机的 3D 行人定位:一种可推广的方法
行人检测是许多领域的关键问题,例如智能城市、监控、监控、自动驾驶和机器人技术。过去几年,基于 AI 的方法在该领域取得了巨大进展,但良好的性能仅限于与训练数据集匹配的数据。我们提出了一种不需要使用来自目标场景的数据进行训练的多摄像头 3D 行人检测方法。我们方法的核心思想在于将多个视图中的一致性公式化为图形集团覆盖问题。我们使用一种基于人体姿势和来自现成单目检测器的人的边界框的新方法来估计图像平面上的行人地面位置。然后,我们将这些位置投影到地平面上,并将它们与图论中的团覆盖问题的新公式融合。我们提出了一种新的顶点排序策略来定义基于检测距离和顶点度的融合优先级。我们还提出了一个可选步骤,通过使用域可概括的人员重新识别模型在融合过程中利用行人外观。最后,我们使用基于关键点三角测量的方法计算每个检测到的行人的最终 3D 地面坐标。我们在具有挑战性的 WILDTRACK 和 MultiviewX 数据集上评估了所提出的方法。我们提出的方法在通用性方面明显优于现有技术。它获得的 MODA 分别比 WILDTRACK 和 MultiviewX 上现有的最佳可概括检测技术好约 15% 和 2%。我们还提出了一个可选步骤,通过使用域可概括的人员重新识别模型在融合过程中利用行人外观。最后,我们使用基于关键点三角测量的方法计算每个检测到的行人的最终 3D 地面坐标。我们在具有挑战性的 WILDTRACK 和 MultiviewX 数据集上评估了所提出的方法。我们提出的方法在通用性方面明显优于现有技术。它获得的 MODA 分别比 WILDTRACK 和 MultiviewX 上现有的最佳可概括检测技术好约 15% 和 2%。我们还提出了一个可选步骤,通过使用域可概括的人员重新识别模型在融合过程中利用行人外观。最后,我们使用基于关键点三角测量的方法计算每个检测到的行人的最终 3D 地面坐标。我们在具有挑战性的 WILDTRACK 和 MultiviewX 数据集上评估了所提出的方法。我们提出的方法在通用性方面明显优于现有技术。它获得的 MODA 分别比 WILDTRACK 和 MultiviewX 上现有的最佳可概括检测技术好约 15% 和 2%。我们使用基于关键点三角测量的方法计算每个检测到的行人的最终 3D 地面坐标。我们在具有挑战性的 WILDTRACK 和 MultiviewX 数据集上评估了所提出的方法。我们提出的方法在通用性方面明显优于现有技术。它获得的 MODA 分别比 WILDTRACK 和 MultiviewX 上现有的最佳可概括检测技术好约 15% 和 2%。我们使用基于关键点三角测量的方法计算每个检测到的行人的最终 3D 地面坐标。我们在具有挑战性的 WILDTRACK 和 MultiviewX 数据集上评估了所提出的方法。我们提出的方法在通用性方面明显优于现有技术。它获得的 MODA 分别比 WILDTRACK 和 MultiviewX 上现有的最佳可概括检测技术好约 15% 和 2%。










































 京公网安备 11010802027423号
京公网安备 11010802027423号