EURASIP Journal on Advances in Signal Processing ( IF 1.9 ) Pub Date : 2022-07-07 , DOI: 10.1186/s13634-022-00887-y Qiubin Lin , Wenming Cao , Zhiquan He
|
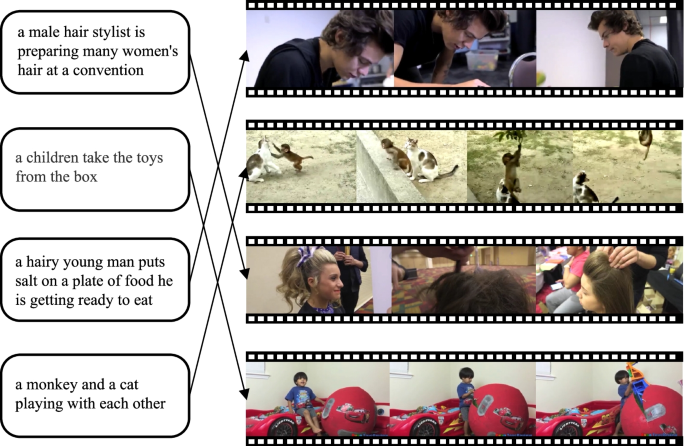
The vast amount of videos on the Internet makes efficient and accurate text–video retrieval tasks increasingly important. The current methods leverage a high-dimensional space to align video and text for these tasks. However, a high-dimensional space cannot fully use different levels of information in videos and text. In this paper, we put forward a method called level-wise aligned dual networks (LADNs) for text–video retrieval. LADN uses four common latent spaces to improve the performance of text–video retrieval and utilizes the semantic concept space to increase the interpretability of the model. Specifically, LADN first extracts different levels of information, including global, local, temporal, and spatial–temporal information, from videos and text. Then, they are mapped into four different latent spaces and one semantic space. Finally, LADN aligns different levels of information in various spaces. Extensive experiments conducted on three widely used datasets, including MSR-VTT, VATEX, and TRECVID AVS 2016-2018, demonstrate that our proposed approach is superior to several state-of-the-art text–video retrieval approaches.
中文翻译:
用于文本-视频检索的水平对齐双网络
互联网上海量的视频使得高效准确的文本视频检索任务变得越来越重要。当前的方法利用高维空间来对齐这些任务的视频和文本。然而,高维空间不能充分利用视频和文本中不同层次的信息。在本文中,我们提出了一种称为水平对齐双网络(LADNs)的文本视频检索方法。LADN 使用四个常见的潜在空间来提高文本-视频检索的性能,并利用语义概念空间来增加模型的可解释性。具体来说,LADN 首先从视频和文本中提取不同层次的信息,包括全局、局部、时间和时空信息。然后,它们被映射到四个不同的潜在空间和一个语义空间。最后,LADN 将不同空间中不同级别的信息对齐。在三个广泛使用的数据集(包括 MSR-VTT、VATEX 和 TRECVID AVS 2016-2018)上进行的广泛实验表明,我们提出的方法优于几种最先进的文本视频检索方法。


























 京公网安备 11010802027423号
京公网安备 11010802027423号