Biochemical Genetics ( IF 2.1 ) Pub Date : 2022-06-27 , DOI: 10.1007/s10528-022-10232-5 Wei Fan 1 , Xiaoyun Chen 1 , Ruiping Li 1 , Rongfang Zheng 1 , Yunyun Wang 2 , Yuzhen Guo 1
|
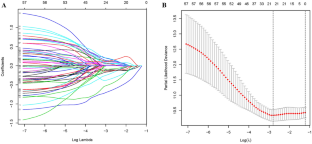
This study explored prognostic genes of ovarian cancer and built a prognostic model based on these genes to predict patient’s survival, which is of great significance for improving treatment of ovarian cancer. GSE26712 dataset was downloaded from Gene Expression Omnibus database as training set, while OV-AU dataset was downloaded from ICGC website as validation set. All genes in GSE26712 were analyzed by univariate Cox regression, Lasso regression, and multivariate Cox regression analyses. Then prognosis-related feature genes were screened to construct a multivariate risk model. Meanwhile, Kyoto Encyclopedia of Genes and Genomes pathway enrichment analysis was performed on samples in the high/low-risk groups using Gene Set Enrichment Analysis (GSEA) software. Finally, survival curve and receiver operating characteristic curve were drawn to verify the validity of the model. Ten feature genes related to prognosis of ovarian cancer were obtained: CMTM6, COLGALT1, F2R, GPR39, IGFBP3, RNF121, MTMR9, ORAI2, SNAI2, ZBTB16. GSEA enrichment analysis showed that there were notable differences in biological pathways such as gap junctions and homologous recombination between the high/low-risk groups. Through further verification of training set and validation set, the 10-gene prognostic model was found to be effective for the prognosis of ovarian cancer patients. In this study, we constructed a 10-gene prognostic model which predicted the prognosis of ovarian cancer patients well by integrating clinical prognostic parameters. It may have certain reference value for subsequent clinical treatment research of ovarian cancer patients and help in clinical treatment decision-making.
中文翻译:
基于基因表达综合数据库基因表达谱的卵巢癌预后风险模型
本研究探索卵巢癌的预后基因,并基于这些基因建立预后模型来预测患者的生存,对于提高卵巢癌的治疗水平具有重要意义。GSE26712 数据集从 Gene Expression Omnibus 数据库下载作为训练集,而 OV-AU 数据集从 ICGC 网站下载作为验证集。GSE26712 中的所有基因均通过单变量 Cox 回归、Lasso 回归和多变量 Cox 回归分析进行分析。然后筛选与预后相关的特征基因,构建多变量风险模型。同时,使用基因集富集分析(GSEA)软件对高/低风险组样本进行了京都基因和基因组百科全书通路富集分析。最后,绘制生存曲线和受试者工作特征曲线,验证模型的有效性。获得与卵巢癌预后相关的10个特征基因:CMTM6、COLGALT1、F2R、GPR39、IGFBP3、RNF121、MTMR9、ORAI2、SNAI2、ZBTB16。GSEA富集分析表明,高/低危人群在缝隙连接、同源重组等生物学途径上存在显着差异。通过训练集和验证集的进一步验证,发现10基因预后模型对卵巢癌患者的预后有效。在这项研究中,我们构建了一个 10 基因预后模型,该模型通过整合临床预后参数来很好地预测卵巢癌患者的预后。










































 京公网安备 11010802027423号
京公网安备 11010802027423号