Lifetime Data Analysis ( IF 1.3 ) Pub Date : 2022-06-24 , DOI: 10.1007/s10985-022-09559-3 Mei-Cheng Wang 1 , Yuxin Zhu 2
|
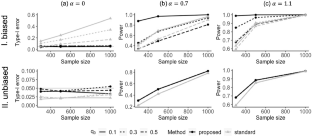
Cross-sectionally sampled data with binary disease outcome are commonly analyzed in observational studies to identify the relationship between covariates and disease outcome. A cross-sectional population is defined as a population of living individuals at the sampling or observational time. It is generally understood that binary disease outcome from cross-sectional data contains less information than longitudinally collected time-to-event data, but there is insufficient understanding as to whether bias can possibly exist in cross-sectional data and how the bias is related to the population risk of interest. Wang and Yang (2021) presented the complexity and bias in cross-sectional data with binary disease outcome with detailed analytical explorations into the data structure. As the distribution of the cross-sectional binary outcome is quite different from the population risk distribution, bias can arise when using cross-sectional data analysis to draw inference for population risk. In this paper we argue that the commonly adopted age-specific risk probability is biased for the estimation of population risk and propose an outcome reassignment approach which reassigns a portion of the observed binary outcome, 0 or 1, to the other disease category. A sign test and a semiparametric pseudo-likelihood method are developed for analyzing cross-sectional data using the OR approach. Simulations and an analysis based on Alzheimer’s Disease data are presented to illustrate the proposed methods.
中文翻译:
通过对具有二元疾病结果的横截面数据的结果重新分配进行偏差校正
具有二元疾病结果的横断面抽样数据通常在观察性研究中进行分析,以确定协变量与疾病结果之间的关系。横截面人口被定义为抽样或观察时间的活个体人口。人们普遍认为,与纵向收集的事件发生时间数据相比,来自横断面数据的二元疾病结果包含的信息较少,但对于横断面数据中是否可能存在偏倚以及偏倚与感兴趣的人群风险。Wang 和 Yang (2021) 通过对数据结构的详细分析探索,提出了具有二元疾病结果的横截面数据的复杂性和偏差。由于横截面二元结果的分布与人群风险分布完全不同,因此在使用横截面数据分析来推断人群风险时可能会出现偏差。在本文中,我们认为通常采用的特定年龄风险概率对人口风险的估计存在偏差,并提出了一种结果重新分配方法,该方法将观察到的二元结果的一部分(0 或 1)重新分配给其他疾病类别。开发了符号检验和半参数伪似然方法,用于使用 OR 方法分析横截面数据。提出了基于阿尔茨海默病数据的模拟和分析来说明所提出的方法。在本文中,我们认为通常采用的特定年龄风险概率对人口风险的估计存在偏差,并提出了一种结果重新分配方法,该方法将观察到的二元结果的一部分(0 或 1)重新分配给其他疾病类别。开发了符号检验和半参数伪似然方法,用于使用 OR 方法分析横截面数据。提出了基于阿尔茨海默病数据的模拟和分析来说明所提出的方法。在本文中,我们认为通常采用的特定年龄风险概率对人口风险的估计存在偏差,并提出了一种结果重新分配方法,该方法将观察到的二元结果的一部分(0 或 1)重新分配给其他疾病类别。开发了符号检验和半参数伪似然方法,用于使用 OR 方法分析横截面数据。提出了基于阿尔茨海默病数据的模拟和分析来说明所提出的方法。开发了符号检验和半参数伪似然方法,用于使用 OR 方法分析横截面数据。提出了基于阿尔茨海默病数据的模拟和分析来说明所提出的方法。开发了符号检验和半参数伪似然方法,用于使用 OR 方法分析横截面数据。提出了基于阿尔茨海默病数据的模拟和分析来说明所提出的方法。


























 京公网安备 11010802027423号
京公网安备 11010802027423号