Nature Machine Intelligence ( IF 18.8 ) Pub Date : 2022-06-22 , DOI: 10.1038/s42256-022-00499-z Noelia Ferruz , Birte Höcker
|
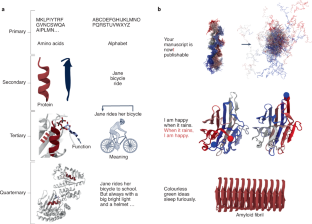
The twenty-first century is presenting humankind with unprecedented environmental and medical challenges. The ability to design novel proteins tailored for specific purposes would potentially transform our ability to respond to these issues in a timely manner. Recent advances in the field of artificial intelligence are now setting the stage to make this goal achievable. Protein sequences are inherently similar to natural languages: amino acids arrange in a multitude of combinations to form structures that carry function, the same way as letters form words and sentences carry meaning. Accordingly, it is not surprising that, throughout the history of natural language processing (NLP), many of its techniques have been applied to protein research problems. In the past few years we have witnessed revolutionary breakthroughs in the field of NLP. The implementation of transformer pre-trained models has enabled text generation with human-like capabilities, including texts with specific properties such as style or subject. Motivated by its considerable success in NLP tasks, we expect dedicated transformers to dominate custom protein sequence generation in the near future. Fine-tuning pre-trained models on protein families will enable the extension of their repertoires with novel sequences that could be highly divergent but still potentially functional. The combination of control tags such as cellular compartment or function will further enable the controllable design of novel protein functions. Moreover, recent model interpretability methods will allow us to open the ‘black box’ and thus enhance our understanding of folding principles. Early initiatives show the enormous potential of generative language models to design functional sequences. We believe that using generative text models to create novel proteins is a promising and largely unexplored field, and we discuss its foreseeable impact on protein design.
中文翻译:
具有语言模型的可控蛋白质设计
二十一世纪给人类带来了前所未有的环境和医学挑战。为特定目的设计新蛋白质的能力可能会改变我们及时应对这些问题的能力。人工智能领域的最新进展正在为实现这一目标奠定基础。蛋白质序列本质上类似于自然语言:氨基酸以多种组合排列形成具有功能的结构,就像字母构成单词和句子具有含义一样。因此,在自然语言处理 (NLP) 的整个历史中,它的许多技术已应用于蛋白质研究问题也就不足为奇了。在过去的几年里,我们见证了 NLP 领域的革命性突破。Transformer 预训练模型的实施使文本生成具有类人能力,包括具有特定属性(如样式或主题)的文本。受其在 NLP 任务中取得巨大成功的推动,我们预计专用转换器将在不久的将来主导定制蛋白质序列的生成。对蛋白质家族的预训练模型进行微调将使他们能够使用可能高度不同但仍具有潜在功能的新序列来扩展它们的库。细胞区室或功能等控制标签的组合将进一步实现新蛋白质功能的可控设计。此外,最近的模型可解释性方法将使我们能够打开“黑匣子”,从而增强我们对折叠原理的理解。早期的举措显示了生成语言模型在设计功能序列方面的巨大潜力。我们相信,使用生成文本模型来创建新的蛋白质是一个很有前途且很大程度上尚未探索的领域,我们讨论了它对蛋白质设计的可预见影响。









































 京公网安备 11010802027423号
京公网安备 11010802027423号