Medical Image Analysis ( IF 10.7 ) Pub Date : 2022-06-17 , DOI: 10.1016/j.media.2022.102515 Feng Gao 1 , Minhao Hu 2 , Min-Er Zhong 1 , Shixiang Feng 2 , Xuwei Tian 3 , Xiaochun Meng 4 , Ma-Yi-di-Li Ni-Jia-Ti 5 , Zeping Huang 1 , Minyi Lv 1 , Tao Song 2 , Xiaofan Zhang 6 , Xiaoguang Zou 3 , Xiaojian Wu 1
|
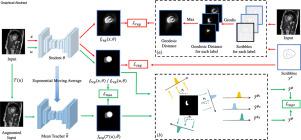
Since segmentation labeling is usually time-consuming and annotating medical images requires professional expertise, it is laborious to obtain a large-scale, high-quality annotated segmentation dataset. We propose a novel weakly- and semi-supervised framework named SOUSA (Segmentation Only Uses Sparse Annotations), aiming at learning from a small set of sparse annotated data and a large amount of unlabeled data. The proposed framework contains a teacher model and a student model. The student model is weakly supervised by scribbles and a Geodesic distance map derived from scribbles. Meanwhile, a large amount of unlabeled data with various perturbations are fed to student and teacher models. The consistency of their output predictions is imposed by Mean Square Error (MSE) loss and a carefully designed Multi-angle Projection Reconstruction (MPR) loss. Extensive experiments are conducted to demonstrate the robustness and generalization ability of our proposed method. Results show that our method outperforms weakly- and semi-supervised state-of-the-art methods on multiple datasets. Furthermore, our method achieves a competitive performance with some fully supervised methods with dense annotation when the size of the dataset is limited.
中文翻译:
分割只使用稀疏注释:医学图像中的统一弱和半监督学习
由于分割标注通常很耗时,并且注释医学图像需要专业知识,因此获取大规模、高质量的注释分割数据集非常费力。我们提出了一种名为 SOUSA(Segmentation Only Uses Sparse Annotations)的新型弱监督和半监督框架,旨在从一小部分稀疏注释数据和大量未标记数据中学习。所提出的框架包含一个教师模型和一个学生模型。学生模型受到涂鸦和从涂鸦导出的测地距离图的弱监督。同时,将大量具有各种扰动的未标记数据提供给学生和教师模型。它们的输出预测的一致性是由均方误差 (MSE) 损失和精心设计的多角度投影重建 (MPR) 损失决定的。进行了广泛的实验以证明我们提出的方法的鲁棒性和泛化能力。结果表明,我们的方法在多个数据集上优于弱监督和半监督的最先进方法。此外,当数据集的大小有限时,我们的方法与一些具有密集注释的完全监督方法取得了竞争性能。









































 京公网安备 11010802027423号
京公网安备 11010802027423号