Journal of Electronic Testing ( IF 1.1 ) Pub Date : 2022-06-09 , DOI: 10.1007/s10836-022-06000-3 Shravani Chandaka , Balaji Narayanam
|
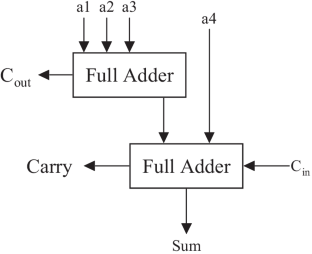
In this research paper, approximate multipliers are designed to reduce the computational time and power delay product. However, there is a high possibility to further optimize the area and power using the modified Wallace Tree Multiplier (MWTM). This research paper proposes, two modified approximate 4:2 compressors are used for partial product addition in multipliers. Using the proposed MWTM, it is observed that Normalized Error Distance (NMED), Mean Relative Error Distance (MRED) and Power Delay Product (PDP) are reduced. The proposed architectures are synthesized using 90-nm CMOS standard cells. Modified Wallace tree multipliers of various sizes (8, 16 and 32 bit) are designed and their performance is compared with the existing general multipliers. The synthesis results of 8-bit MWTM shows that on an average the delay and power are reduced in the range of 10%–55.37% and 13.03%–13.78% when compared to existing multipliers. Moreover, for 16-bit MWTM shows that on an average the delay and power are reduced in the range of 0.11%–3.12% and 0.28%–6.59%. And 32-bit MWTM shows that on an average the power is reduced in the range of about 8%–27.99%. The image processing operations image blending, image smoothening and edge detection are implemented using the proposed MWTM. The results proved the efficiency of the MWTM.
中文翻译:
用于图像处理应用的硬件高效近似乘法器架构
在本研究论文中,近似乘法器旨在减少计算时间和功率延迟积。但是,使用修改后的华莱士树乘法器 (MWTM) 进一步优化面积和功率的可能性很大。本研究论文提出,使用两个改进的近似 4:2 压缩机在乘法器中进行部分乘积相加。使用所提出的 MWTM,可以观察到归一化误差距离 (NMED)、平均相对误差距离 (MRED) 和功率延迟积 (PDP) 减少了。所提出的架构是使用 90-nm CMOS 标准单元合成的。设计了各种尺寸(8位、16位和32位)的改进的华莱士树乘法器,并与现有的通用乘法器进行了性能比较。8位MWTM的综合结果表明,与现有乘法器相比,平均延迟和功耗降低了10%~55.37%和13.03%~13.78%。此外,对于 16 位 MWTM,延迟和功率平均降低了 0.11%–3.12% 和 0.28%–6.59%。而 32 位 MWTM 显示,平均功率降低了大约 8%–27.99%。图像处理操作图像混合、图像平滑和边缘检测是使用提出的 MWTM 实现的。结果证明了MWTM的效率。而 32 位 MWTM 显示,平均功率降低了大约 8%–27.99%。图像处理操作图像混合、图像平滑和边缘检测是使用提出的 MWTM 实现的。结果证明了MWTM的效率。而 32 位 MWTM 显示,平均功率降低了大约 8%–27.99%。图像处理操作图像混合、图像平滑和边缘检测是使用提出的 MWTM 实现的。结果证明了MWTM的效率。










































 京公网安备 11010802027423号
京公网安备 11010802027423号