当前位置:
X-MOL 学术
›
J. Chem. Theory Comput.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Highly Efficient and Accurate Computation of Multiple Orbital Spaces Spanning Fock Matrix Elements on Central and Graphics Processing Units for Application in F12 Theory
Journal of Chemical Theory and Computation ( IF 5.7 ) Pub Date : 2022-06-08 , DOI: 10.1021/acs.jctc.2c00215 Lars Urban 1, 2 , Henryk Laqua 1 , Christian Ochsenfeld 1, 2
Journal of Chemical Theory and Computation ( IF 5.7 ) Pub Date : 2022-06-08 , DOI: 10.1021/acs.jctc.2c00215 Lars Urban 1, 2 , Henryk Laqua 1 , Christian Ochsenfeld 1, 2
Affiliation
|
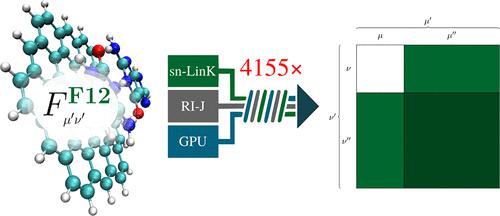
We employ our recently published highly efficient seminumerical exchange (sn-LinK) [Laqua, H.; Thompson, T. H.; Kussmann, J.; Ochsenfeld, C. J. Chem. Theory Comput. 2020, 16, 1456−1468] and integral-direct resolution of the identity Coulomb (RI-J) [Kussmann, J.; Laqua, H.; Ochsenfeld, C. J. Chem. Theory Comput. 2021, 17, 1512−1521] methods to significantly accelerate the computation of the demanding multiple orbital spaces spanning Fock matrix elements present in R12/F12 theory on central and graphics processing units. The errors introduced by RI-J and sn-LinK into the RI-MP2-F12 energy are thoroughly assessed for a variety of basis sets and integration grids. We find that these numerical errors are always below “chemical accuracy” (∼1 mH) even for the coarsest settings and can easily be reduced below 1 μH by employing only moderately large integration grids and RI-J basis sets. Since the number of basis functions of the multiple orbital spaces is notably larger compared with conventional Hartree–Fock theory, the efficiency gains from the superior basis scaling of RI-J and sn-LinK (O(Nbas2) instead of O(Nbas4) for both) are even more significant, with maximum speedup factors of 37 000 for RI-J and 4500 for sn-LinK. In total, the multiple orbital spaces spanning Fock matrix evaluation of the largest tested structure using a triple-ζ F12 basis set (5058 AO basis functions, 9267 CABS basis functions) is accelerated over 1575× using CPUs and over 4155× employing GPUs.
中文翻译:

在 F12 理论中应用的中央和图形处理单元上跨越 Fock 矩阵元素的多个轨道空间的高效和准确计算
我们采用了我们最近发布的高效半数字交换 (sn-LinK) [拉夸,H。汤普森,TH;库斯曼,J。奥森菲尔德,C. J.化学。理论计算。 2020 , 16 , 1456−1468] 和恒等库仑 (RI-J) 的积分直接分辨率 [库斯曼,J。拉夸,H。奥森菲尔德,C. J.化学。理论计算。 2021年17 月, 1512−1521] 方法显着加速了对中央和图形处理单元的 R12/F12 理论中存在的跨越 Fock 矩阵元素的苛刻的多个轨道空间的计算。RI-J 和 sn-LinK 引入 RI-MP2-F12 能量的误差针对各种基组和积分网格进行了全面评估。我们发现,即使对于最粗略的设置,这些数值误差也始终低于“化学精度”(~1 mH),并且可以通过仅使用中等大的积分网格和 RI-J 基组轻松降低到 1 μH 以下。由于与传统的 Hartree-Fock 理论相比,多个轨道空间的基函数数量显着增加,因此 RI-J 和 sn-LinK ( O ( N bas2 ) 而不是O ( N bas 4 ) 对于两者)更为重要,RI-J 的最大加速因子为 37 000,sn-LinK 的最大加速因子为 4500。总的来说,使用三重ζ F12 基组(5058 个 AO 基函数,9267 个 CABS 基函数)跨越最大测试结构的 Fock 矩阵评估的多个轨道空间使用 CPU 加速超过 1575 倍,使用 GPU 加速超过 4155 倍。
更新日期:2022-06-08
中文翻译:
在 F12 理论中应用的中央和图形处理单元上跨越 Fock 矩阵元素的多个轨道空间的高效和准确计算
我们采用了我们最近发布的高效半数字交换 (sn-LinK) [










































 京公网安备 11010802027423号
京公网安备 11010802027423号