EURASIP Journal on Wireless Communications and Networking ( IF 2.3 ) Pub Date : 2022-06-04 , DOI: 10.1186/s13638-022-02124-4 Liang Dong , Yuchen Qian , Yuan Xing
|
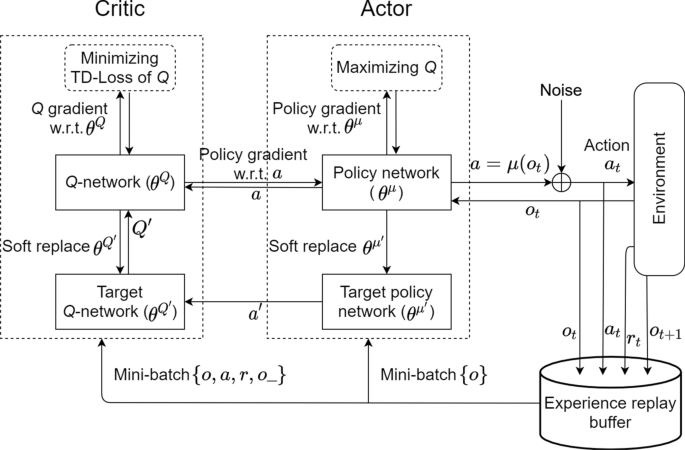
When primary users of the spectrum use frequency channels intermittently, secondary users can selectively transmit without interfering with the primary users. The secondary users adjust the transmission power allocation on the frequency channels to maximize their information rate while reducing channel conflicts with the primary users. In this paper, the secondary users do not know the spectrum usage by the primary users or the channel gains of the secondary users. Based on the conflict warnings from the primary users and the signal-to-interference-plus-noise ratio measurement at the receiver, the secondary users adapt and improve spectrum utilization through deep reinforcement learning. The secondary users adopt the actor-critic deep deterministic policy gradient algorithm to overcome the challenges of large state space and large action space in reinforcement learning with continuous-valued actions. In addition, multiple secondary users implement multi-agent deep reinforcement learning under certain coordination. Numerical results show that the secondary users can successfully adapt to the spectrum environment and learn effective transmission policies.
中文翻译:
通过演员-评论家深度强化学习进行动态频谱访问和共享
当频谱的主用户间歇性地使用频道时,次用户可以选择性地发射而不干扰主用户。次要用户调整频率信道上的发射功率分配,以最大限度地提高其信息速率,同时减少与主要用户的信道冲突。在本文中,次用户不知道主用户的频谱使用情况或次用户的信道增益。基于主要用户的冲突警告和接收端的信干噪比测量,次要用户通过深度强化学习适应和提高频谱利用率。二级用户采用actor-critic深度确定性策略梯度算法来克服连续值动作强化学习中大状态空间和大动作空间的挑战。此外,多个二级用户在一定的协调下实现多智能体深度强化学习。数值结果表明,二级用户能够成功地适应频谱环境并学习有效的传输策略。










































 京公网安备 11010802027423号
京公网安备 11010802027423号