Medical Image Analysis ( IF 10.7 ) Pub Date : 2022-05-24 , DOI: 10.1016/j.media.2022.102487 Chu Han 1 , Jiatai Lin 2 , Jinhai Mai 3 , Yi Wang 4 , Qingling Zhang 5 , Bingchao Zhao 3 , Xin Chen 6 , Xipeng Pan 1 , Zhenwei Shi 1 , Zeyan Xu 3 , Su Yao 5 , Lixu Yan 5 , Huan Lin 3 , Xiaomei Huang 3 , Changhong Liang 3 , Guoqiang Han 7 , Zaiyi Liu 3
|
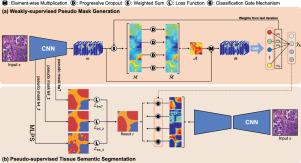
Tissue-level semantic segmentation is a vital step in computational pathology. Fully-supervised models have already achieved outstanding performance with dense pixel-level annotations. However, drawing such labels on the giga-pixel whole slide images is extremely expensive and time-consuming. In this paper, we use only patch-level classification labels to achieve tissue semantic segmentation on histopathology images, finally reducing the annotation efforts. We propose a two-step model including a classification and a segmentation phases. In the classification phase, we propose a CAM-based model to generate pseudo masks by patch-level labels. In the segmentation phase, we achieve tissue semantic segmentation by our propose Multi-Layer Pseudo-Supervision. Several technical novelties have been proposed to reduce the information gap between pixel-level and patch-level annotations. As a part of this paper, we introduce a new weakly-supervised semantic segmentation (WSSS) dataset for lung adenocarcinoma (LUAD-HistoSeg). We conduct several experiments to evaluate our proposed model on two datasets. Our proposed model outperforms five state-of-the-art WSSS approaches. Note that we can achieve comparable quantitative and qualitative results with the fully-supervised model, with only around a 2% gap for MIoU and FwIoU. By comparing with manual labeling on a randomly sampled 100 patches dataset, patch-level labeling can greatly reduce the annotation time from hours to minutes. The source code and the released datasets are available at: https://github.com/ChuHan89/WSSS-Tissue.
中文翻译:
使用补丁级分类标签的组织病理学组织语义分割的多层伪监督
组织级语义分割是计算病理学中的重要一步。全监督模型已经通过密集的像素级注释实现了出色的性能。然而,在千兆像素的整个幻灯片图像上绘制这样的标签非常昂贵且耗时。在本文中,我们仅使用补丁级分类标签来实现组织病理学图像的组织语义分割,最终减少了注释工作。我们提出了一个两步模型,包括分类和分割阶段。在分类阶段,我们提出了一个基于 CAM 的模型,通过补丁级标签生成伪掩码。在分割阶段,我们通过我们提出的多层伪监督来实现组织语义分割。已经提出了一些技术新颖性来减少像素级和补丁级注释之间的信息差距。作为本文的一部分,我们介绍了一种新的肺腺癌弱监督语义分割 (WSSS) 数据集 (LUAD-HistoSeg)。我们进行了几次实验来评估我们在两个数据集上提出的模型。我们提出的模型优于五种最先进的 WSSS 方法。请注意,我们可以使用全监督模型获得可比较的定量和定性结果,MIoU 和 FwIoU 的差距只有 2% 左右。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。作为本文的一部分,我们介绍了一种新的肺腺癌弱监督语义分割 (WSSS) 数据集 (LUAD-HistoSeg)。我们进行了几次实验来评估我们在两个数据集上提出的模型。我们提出的模型优于五种最先进的 WSSS 方法。请注意,我们可以使用全监督模型获得可比较的定量和定性结果,MIoU 和 FwIoU 的差距只有 2% 左右。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。作为本文的一部分,我们介绍了一种新的肺腺癌弱监督语义分割 (WSSS) 数据集 (LUAD-HistoSeg)。我们进行了几次实验来评估我们在两个数据集上提出的模型。我们提出的模型优于五种最先进的 WSSS 方法。请注意,我们可以使用全监督模型获得可比较的定量和定性结果,MIoU 和 FwIoU 的差距只有 2% 左右。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。我们进行了几次实验来评估我们在两个数据集上提出的模型。我们提出的模型优于五种最先进的 WSSS 方法。请注意,我们可以使用全监督模型获得可比较的定量和定性结果,MIoU 和 FwIoU 的差距只有 2% 左右。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。我们进行了几次实验来评估我们在两个数据集上提出的模型。我们提出的模型优于五种最先进的 WSSS 方法。请注意,我们可以使用全监督模型获得可比较的定量和定性结果,MIoU 和 FwIoU 的差距只有 2% 左右。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。通过与在随机采样的 100 个补丁数据集上进行手动标注相比,补丁级别的标注可以将标注时间从几小时大幅缩短到几分钟。源代码和发布的数据集可在:https://github.com/ChuHan89/WSSS-Tissue 获得。










































 京公网安备 11010802027423号
京公网安备 11010802027423号