Journal of Real-Time Image Processing ( IF 2.9 ) Pub Date : 2022-05-09 , DOI: 10.1007/s11554-022-01217-z Qinghua Zhao 1 , Qi Peng 1 , Yiqi Zhuang 1
|
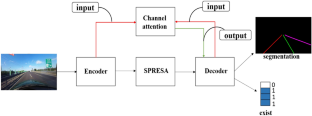
For self-driving cars and advanced driver assistance systems, lane detection is imperative. On the one hand, numerous current lane line detection algorithms perform dense pixel-by-pixel prediction followed by complex post-processing. On the other hand, as lane lines only account for a small part of the whole image, there are only very subtle and sparse signals, and information is lost during long-distance transmission. Therefore, it is difficult for an ordinary convolutional neural network to resolve challenging scenes, such as severe occlusion, congested roads, and poor lighting conditions. To address these issues, in this study, we propose an encoder–decoder architecture based on an attention mechanism. The encoder module is employed to initially extract the lane line features. We propose a spatial recurrent feature-shift aggregator module to further enrich the lane line features, which transmits information from four directions (up, down, left, and right). In addition, this module contains the spatial attention feature that focuses on useful information for lane line detection and reduces redundant computations. In particular, to reduce the occurrence of incorrect predictions and the need for post-processing, we add channel attention between the encoding and decoding. It processes encoding and decoding to obtain multidimensional attention information, respectively. Our method achieved novel results on two popular lane detection benchmarks (CULane F1-measure 76.2, TuSimple accuracy 96.85%), which can reach 48 frames per second and meet the real-time requirements of autonomous driving.
中文翻译:
基于注意力机制编解码器结构的车道线检测
对于自动驾驶汽车和高级驾驶辅助系统,车道检测必不可少。一方面,许多当前的车道线检测算法执行密集的逐像素预测,然后进行复杂的后处理。另一方面,由于车道线仅占整幅图像的一小部分,因此信号非常微妙和稀疏,在长距离传输过程中信息丢失。因此,普通的卷积神经网络很难解决具有挑战性的场景,例如严重的遮挡、拥堵的道路和恶劣的光照条件。为了解决这些问题,在本研究中,我们提出了一种基于注意力机制的编码器-解码器架构。编码器模块用于最初提取车道线特征。我们提出了一个空间循环特征转移聚合器模块,以进一步丰富车道线特征,从四个方向(上、下、左和右)传输信息。此外,该模块包含空间注意力功能,专注于车道线检测的有用信息并减少冗余计算。特别是,为了减少错误预测的发生和后处理的需要,我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。它从四个方向(上、下、左和右)传输信息。此外,该模块包含空间注意力功能,专注于车道线检测的有用信息并减少冗余计算。特别是,为了减少错误预测的发生和后处理的需要,我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。它从四个方向(上、下、左和右)传输信息。此外,该模块包含空间注意力功能,专注于车道线检测的有用信息并减少冗余计算。特别是,为了减少错误预测的发生和后处理的需要,我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。该模块包含空间注意力功能,专注于车道线检测的有用信息并减少冗余计算。特别是,为了减少错误预测的发生和后处理的需要,我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。该模块包含空间注意力功能,专注于车道线检测的有用信息并减少冗余计算。特别是,为了减少错误预测的发生和后处理的需要,我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。我们在编码和解码之间添加了通道注意力。它分别处理编码和解码以获得多维注意力信息。我们的方法在两个流行的车道检测基准(CULane F1-measure 76.2,TuSimple 准确率 96.85%)上取得了新颖的结果,可以达到每秒 48 帧,满足自动驾驶的实时性要求。










































 京公网安备 11010802027423号
京公网安备 11010802027423号