Pattern Recognition Letters ( IF 3.9 ) Pub Date : 2022-05-07 , DOI: 10.1016/j.patrec.2022.04.040 Abdelhay Zoizou 1 , Arsalane Zarghili 1 , Ilham Chaker 1
|
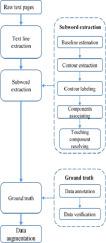
The digitalization of historical documents is vital to preserving their content and the historical memory of nations. Although, the results of historical Arabic handwritten text recognition and word spotting are still unsatisfactory. The increasing research efforts during the last few years are still not sufficient since handwriting recognition systems rely heavily on robust databases. In this paper, we present a new contour-based method of subword extraction from Arabic historical documents and a novel database of Arabic historical subwords MOJ-DB. The proposed method of subword extraction includes a process of touching components resolving. It proved high performance and consistency while tested on different databases and compared with other methods from the literature. The proposed database contains 560000 subwords distributed on 5600 different classes. It was built using 64 pages extracted from 10 books written in the 17th and 16th centuries. MOJ-DB database is divided into three sets; 70%,20%, and 10% for training, testing, and validation, respectively. Ground truth is established iteratively to guarantee minimal error. It includes information about the subword as of the sourcebook and page. We conducted several experiments to verify the robustness of the proposed database as well as the validity of the segmentation process. The database is freely available for the public research community. It can be used for word and subword recognition, word spotting, subword extraction, and database construction.
中文翻译:
MOJ-DB:一个新的阿拉伯语历史笔迹数据库和一种新的子词提取方法
历史文献的数字化对于保存其内容和国家的历史记忆至关重要。尽管如此,历史上的阿拉伯语手写文本识别和单词识别的结果仍然不能令人满意。由于手写识别系统严重依赖强大的数据库,因此过去几年不断增加的研究工作仍然不够。在本文中,我们提出了一种新的基于轮廓的从阿拉伯历史文献中提取子词的方法和一个新的阿拉伯历史子词数据库 MOJ-DB。所提出的子词提取方法包括一个触摸组件解析的过程。在不同的数据库上进行测试并与文献中的其他方法进行比较时,它证明了高性能和一致性。建议的数据库包含分布在 5600 个不同类别上的 560000 个子词。它是用 64 页从 17 和 16 世纪写的 10 本书中提取的。MOJ-DB数据库分为三组;70%、20% 和 10% 分别用于训练、测试和验证。基本事实是迭代建立的,以保证最小的错误。它包括关于源书和页面的子词的信息。我们进行了几次实验来验证所提出的数据库的稳健性以及分割过程的有效性。该数据库可供公共研究界免费使用。它可用于单词和子词识别、单词定位、子词提取和数据库构建。MOJ-DB数据库分为三组;70%、20% 和 10% 分别用于训练、测试和验证。基本事实是迭代建立的,以保证最小的错误。它包括关于源书和页面的子词的信息。我们进行了几次实验来验证所提出的数据库的稳健性以及分割过程的有效性。该数据库可供公共研究界免费使用。它可用于单词和子词识别、单词定位、子词提取和数据库构建。MOJ-DB数据库分为三组;70%、20% 和 10% 分别用于训练、测试和验证。基本事实是迭代建立的,以保证最小的错误。它包括关于源书和页面的子词的信息。我们进行了几次实验来验证所提出的数据库的稳健性以及分割过程的有效性。该数据库可供公共研究界免费使用。它可用于单词和子词识别、单词定位、子词提取和数据库构建。我们进行了几次实验来验证所提出的数据库的稳健性以及分割过程的有效性。该数据库可供公共研究界免费使用。它可用于单词和子词识别、单词定位、子词提取和数据库构建。我们进行了几次实验来验证所提出的数据库的稳健性以及分割过程的有效性。该数据库可供公共研究界免费使用。它可用于单词和子词识别、单词定位、子词提取和数据库构建。










































 京公网安备 11010802027423号
京公网安备 11010802027423号