当前位置:
X-MOL 学术
›
Adv. Theory Simul.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
A Decreasing Scaling Transition Scheme from Adam to SGD
Advanced Theory and Simulations ( IF 2.9 ) Pub Date : 2022-04-27 , DOI: 10.1002/adts.202100599 Kun Zeng 1 , Jinlan Liu 2 , Zhixia Jiang 1 , Dongpo Xu 2
Advanced Theory and Simulations ( IF 2.9 ) Pub Date : 2022-04-27 , DOI: 10.1002/adts.202100599 Kun Zeng 1 , Jinlan Liu 2 , Zhixia Jiang 1 , Dongpo Xu 2
Affiliation
|
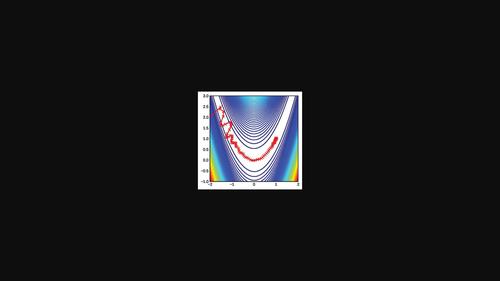
Adaptive gradient algorithm and its variants, such as RMSProp, Adam, AMSGrad, etc., have been widely used in deep learning. Although these algorithms are faster in the early phase of training, their generalization performance is often not as good as stochastic gradient descent (SGD). Hence, a trade-off method of transforming Adam to SGD after a certain iteration to gain the merits of both algorithms is theoretically and practically significant. To that end, a decreasing scaling transition scheme to achieve a smooth and stable transition from Adam to SGD, which is called DSTAdam. The convergence of the proposed DSTAdam is also proved in an online convex setting. Finally, the effectiveness of the DSTAdam is verified on the different datasets. The implementation is available at: https://github.com/kunzeng/DSTAdam.
中文翻译:

从 Adam 到 SGD 的递减缩放过渡方案
自适应梯度算法及其变体,如 RMSProp、Adam、AMSGrad 等,已广泛应用于深度学习。尽管这些算法在训练的早期阶段速度更快,但它们的泛化性能通常不如随机梯度下降(SGD)。因此,在一定的迭代之后将 Adam 转换为 SGD 以获得两种算法的优点的权衡方法在理论上和实践上都具有重要意义。为此,一种递减缩放过渡方案,以实现从 Adam 到 SGD 的平稳过渡,称为 DSTAdam。所提出的 DSTAdam 的收敛性也在在线凸设置中得到证明。最后,在不同的数据集上验证了 DSTAdam 的有效性。该实现可在以下网址获得:https://github.com/kunzeng/DSTAdam。
更新日期:2022-04-27
中文翻译:
从 Adam 到 SGD 的递减缩放过渡方案
自适应梯度算法及其变体,如 RMSProp、Adam、AMSGrad 等,已广泛应用于深度学习。尽管这些算法在训练的早期阶段速度更快,但它们的泛化性能通常不如随机梯度下降(SGD)。因此,在一定的迭代之后将 Adam 转换为 SGD 以获得两种算法的优点的权衡方法在理论上和实践上都具有重要意义。为此,一种递减缩放过渡方案,以实现从 Adam 到 SGD 的平稳过渡,称为 DSTAdam。所提出的 DSTAdam 的收敛性也在在线凸设置中得到证明。最后,在不同的数据集上验证了 DSTAdam 的有效性。该实现可在以下网址获得:https://github.com/kunzeng/DSTAdam。










































 京公网安备 11010802027423号
京公网安备 11010802027423号